Как выбрать трансформатор или подключение светильника
Мебельные светильники становятся незаменимым атрибутом на любой современной кухне – это удобно и функционально! Однако некоторые дизайнеры и покупатели испытывают сложности при заказе светильников из-за необходимости заказа дополнительных проводов или трансформатора. В этой статье мы подробно ответим на наиболее часто задаваемые вопросы.
Почему некоторым светильникам нужен трансформатор, а другим — нет? Потому что, в целом, все светильники делятся на 2 вида по типу рабочего напряжения.
Светильники, работающие от напряжения 220/230 V
Со штекером на конце кабеля
Для подключения такого светильника к электросети 220 V необходим удлинитель-переходник к штекеру с сетевым кабелем и вилкой (см. схему подключения 1.1 и 1.2)
С сетевым кабелем и вилкой
Такой светильник сразу подключается к электросети (см.
Светильники, работающие от напряжения 12/24 V
В этом случае необходим трансформатор с сетевым кабелем и вилкой для понижения напряжения 220 V до нужного уровня в 12 V или 24 V (см. схему подключения 2.1 и 2.2)
Как узнать напряжение светильника?
Рабочее напряжение светильника указано в описании светильника в пункте «Питание». Для удобства заказа светильников и во избежание ошибок всегда смотрите блок «Необходимые товары» в нижней части страницы с продуктом. В нём указаны опции, которые необходимо дополнительно заказать, чтобы правильно подключить светильник к электросети.
Как выбрать нужный трансформатор?
При заказе трансформатора необходимо учитывать суммарную мощность светильников, которые будут подключаться к трансформатору. От этого зависит, сколько светильников можно подключить к трансформатору.
Как определить, сколько светильников можно подключить к трансформатору?
В характеристиках каждого светильника указана мощность лампы, используемой в светильнике (лампа, W), а у каждого трансформатора указана его мощность. Суммарная мощность подключаемых светильников должна быть меньше, чем номинальная мощность трансформатора.
Лампа: 3,5 W. Соответственно, для подключения к сети необходим трансформатор того же производителя с мощностью выше 3,5 W. Например, нам подойдёт трансформатор 15W для подключения до 4-х светильников с сетевым кабелем 2 м с вилкой, так как его мощность 15 W. Тогда возможное количество подключаемых к данному трансформатору светильников: 15 W/3,5 W = 4 светильника. Суммарная мощность светильников: 3,5 W х 4 = 14 W.
Таким образом можно рассчитать суммарную мощность светильников. Если у вас возникли вопросы по выбору светильника или трансформатора звоните нам по телефону или пишите на почту zakaz@duslar.
Внимание!
Трансформатор должен быть от того же производителя, что и светильник! При использовании трансформаторов, не рекомендованных компанией Duslar, правильная работа светильников не гарантируется. Используйте трансформаторы из блока «Необходимые товары» на странице с продуктом.
Самый мощный в мире трансформатор постоянного тока на сверхвысокие напряжения
Корпорация ABB зафиксировала технологическое достижение, с успехом проведя разработку и тестирование мощнейшего на планете преобразовательного трансформатора постоянного тока UHVDC, рассчитанный на супервысокое напряжение 1100 кВ (1,1 миллионов вольт). Он был создан совместно с сетевой китайской корпорацией SGCC, принадлежащей государству. Состоит из нескольких модулей высокого и низкого напряжения.
Назначение
В процессе создания оборудования был разработан план прокладки сверхвысоковольтной линии электропередач постоянного тока по маршруту Чанцзи — Гугуан. По ней будет передаваться электрическая энергия из северо-западных китайских регионов на восток страны. В более общем плане — подобные устройства можно будет устанавливать по всему миру. Они значительно упростят технологию передачи электроэнергии на тысячи километров. Это достигается за счёт повышенного напряжения. Его удаётся получить при помощи технологии HVDC. При этом потери электроэнергии минимальные. И ключевым оборудованием в преобразовательных электрических подстанциях для таких линий станут как раз трансформаторы постоянного тока, подобные разработке ABB. Это высокотехнологичный продукт, готовый к практическому использованию. На данном этапе уже решены стоявшие проблемы — крупные габариты, трудности с изоляцией входов в трансформатор, выделение значительного количества тепла.
По ней будет передаваться электрическая энергия из северо-западных китайских регионов на восток страны. В более общем плане — подобные устройства можно будет устанавливать по всему миру. Они значительно упростят технологию передачи электроэнергии на тысячи километров. Это достигается за счёт повышенного напряжения. Его удаётся получить при помощи технологии HVDC. При этом потери электроэнергии минимальные. И ключевым оборудованием в преобразовательных электрических подстанциях для таких линий станут как раз трансформаторы постоянного тока, подобные разработке ABB. Это высокотехнологичный продукт, готовый к практическому использованию. На данном этапе уже решены стоявшие проблемы — крупные габариты, трудности с изоляцией входов в трансформатор, выделение значительного количества тепла.
По словам руководителя подразделения корпорации ABB Клаудио Фачина, передача большего количества электрической энергии на сверхдлинные расстояния — не единственное назначение преобразовательных трансформаторов UHVDC.
Перспективы развития
Идея разработки подобного оборудования принадлежала китайской компании. Дело в том, что самые крупные города (являющиеся ключевыми потребителями электроэнергии) расположены на востоке страны. При этом большая часть ресурсов энергетики сосредоточена, напротив, на западе и северо-западе. Возникла задача передачи электроэнергии через всю страну с минимальными потерями, и она была успешно решена созданием принципиально нового преобразовательного трансформатора.
Однако такой вопрос стоит не только в Китае, и это обстоятельство — ключ к дальнейшему развитию проекта. Протяжённые территории есть у многих стран мира, и в первую очередь у России. Это отметил и Олег Волков, менеджер по маркетингу представительства ABB в нашей стране. По его словам, Россия является уникальной территорией, на которой громадные расстояния сочетаются с большими перспективами по усовершенствованию электроэнергетического хозяйства. Способ передачи электрической энергии на дальние расстояния в соответствии с технологией HVDC от ABB даст возможность уменьшить потери, повысить надёжность и эффективность работы энергетической системы. Это, в свою очередь, существенно поднимет интерес к России со стороны мировых инвесторов.
Способ передачи электрической энергии на дальние расстояния в соответствии с технологией HVDC от ABB даст возможность уменьшить потери, повысить надёжность и эффективность работы энергетической системы. Это, в свою очередь, существенно поднимет интерес к России со стороны мировых инвесторов.
Помимо нашей страны, перспективами применения сверхвысоковольтной передачи электроэнергии заинтересовались США, Индия, Канада, Бразилия. В перспективе данную технологию можно внедрять не только в пределах одной страны, но и между разными странами — особенно, если у них налажены между собой экономические и политические отношения, имеются общие энергетические стандарты.
27.09.2016, Подключение счетчика электроэнергии в низковольтную сеть большой мощности — 2016 — Блог — Пресс-центр — Компания
В одной из предыдущих статей мы уже рассматривали измерительные трансформаторы тока, их сферы применения, технические характеристики и особенности режима работы.
Как отмечалось ранее, для подключения счетчика в сеть большой мощности (с большими токами) необходимо применять специальные устройства — измерительные трансформаторы тока. Речь идет о низковольтных сетях до 0,66 кВ, где уровень номинального тока 100 А и выше. Счетчики прямого включения не предназначены для использования в таких мощных сетях, поэтому и требуется снизить уровень рабочего тока до величины, удобной для измерения приборами учета — 5 А.
Способ подключения в сеть счетчика, при котором токовые обмотки счетчика подключаются к измерительным выводам трансформатора тока называют полукосвенным. При этом способе подключения счетчика используется рабочее напряжение сети (обмотки напряжения подключаются к электросчетчику напрямую).
Существует также и косвенный способ подключения счетчика, однако он применяется для учета электроэнергии в установках с напряжением более 1 кВ. При косвенном подключении счетчика кроме трансформаторов тока применяются трансформаторы напряжения, снижающие высокое значение напряжение до 100 В.
Класс точности и его значение для учета электроэнергии
Правила Устройства Электроустановок (сокращенно ПУЭ) устанавливают классы точности для трансформаторов тока различных категорий применений. Так, для коммерческого учета должны устанавливаться трансформаторы тока с классом точности не более 0,5, а для технического учета необходим класс точности не выше 1,0.
Также встречаются трансформаторы тока с практически одинаковыми классами точности 0,5 и 0,5S. В чем заключается между ними разница? Погрешность обмотки ТТ с классом точности 0,5 не нормируется ниже 5%. Это значит, что при нагрузке в главной цепи ниже 5% электрическая энергия не будет учитываться. Класс точности 0,5S говорит о том, что трансформатор тока будет передавать сигнал на счетчик при уровне нагрузки не ниже 1%.
Схемы подключения счетчика через трансформаторы тока
Подключить трехфазный счетчик электроэнергии в мощную низковольтную сеть с глухозаземленной нейтралью можно по приведенным ниже схемам.
Цепи тока и напряжения в этой схеме, которую еще называют «десятипроводной» (по количеству используемых проводов), разделены. Подобное разделение цепей напряжения и тока позволяет повысить электробезопасность и легко проверять правильность подключения.
Следующая схема, в которой все выводы И2 измерительных трансформаторов тока соединяются в общую точку и присоединяются к нулевому проводнику, называется «звезда» (т. к. трансформаторы тока соединены по одноименной схеме). Она экономична с точки зрения использования проводов, однако усложняет проверку схемы включения счетчика представителями энергоснабжающих организаций.
«Семипроводная» схема на сегодняшний день является устаревшей, но так или иначе до сих пор встречается. Эта схема, будучи самой экономичной, опасна для обслуживающего персонала и потому должна быть модернизирована до десятипроводной.
Подключения счетчика электроэнергии через переходную испытательную коробку (КИП)
Как указано в ПУЭ (п 1.![]() 5.23.), подключать трехфазные счетчики электроэнергии следует через испытательные коробки, упомянутые выше. Они (коробки испытательные переходные) позволяют производить замену счетчика, не отключая нагрузку, так как все необходимые переключения можно произвести в КИП.
5.23.), подключать трехфазные счетчики электроэнергии следует через испытательные коробки, упомянутые выше. Они (коробки испытательные переходные) позволяют производить замену счетчика, не отключая нагрузку, так как все необходимые переключения можно произвести в КИП.
Также встречаются низковольтные сети с изолированной нейтралью (система IT). Если быть более точным, то в сети с такой системой заземления нейтральный проводник может быть как полностью изолирован, так и заземлен при помощи специальных приборов, обладающих большим электрическим сопротивлением.
Такая система (IT) применяется на объектах, к которым предъявляются высокие требования по надежности и безопасности электроснабжения. Например, изолированная система IT применяется для электрических установок угольных шахт, для мобильных дизельных и бензиновых электростанций, а также для аварийного освещения и электроснабжения больниц. Подключить счетчик электроэнергии к трансформаторам тока в сеть с изолированной нейтралью можно по следующей схеме.
Измерительные трансформаторы тока — это устройства, преобразующие большие значения тока главных цепей до величины 5 А, удобной для измерения счетчиками электроэнергии. Именно это и определяет их основное назначение: питание цепей учета электроэнергии (коммерческий и технический) в мощных установках, там где счетчики прямого включения просто не могут применяться.
Какой полуавтомат выбрать — инвертор или трансформатор • Стройка/Ремонт • Блог • Электроинструменты, инструменты для электрика, садовый и хозяйственный инвентарь в Гродно. Оптовые цены
Общий тренд снижения цен на инверторные сварочники вывел из на одну ступень с трансформаторными. Глаза разбегаются от ассортимента, но выбрать нужно один, причем как всегда на тот, который хочется денег немного не хватает.
Продавцы сварочных аппаратов настаивают на плюсах инверторов и это понятно – они заработать хотят, в то время как автомастера, работающие на трансах, категорически с ними не согласны и менять свои трансформаторные полуавтоматы на инверторы явно не торопятся.
Почему? Причина, в общем-то понятна, форумы по сварке пестрят сообщениями о том, что инверторы «дохнут» чуть ли не в первые дни работы. Но если внимательно почитать такие темы, то, как правило, речь идет о «плохом Китае» или псевдоевропейцах (американцах), это когда бренд зарегистрирован, например, в Европе, а сборку на коленке опять же делают в «плохом Китае».
Одним из достоинств инверторной схемы продавцами предъявляется возможность нормальной работы при скачках напряжения, что является, несомненно, плюсом особенно при нестабильном напряжении в гаражах. С другой стороны это легко лечится включением в цепь стабилизатора напряжения – но, опять дополнительные расходы.
Если ваш выбор лежит в сторону инверторного блока, следует учесть, что некоторые производители для защиты от влаги и пыли заливают плату с электронными элементами лаком или компаундом, что называется по самые уши. В этом есть как плюс – понижается вероятность выхода из строя от пыли и влаги, но и большой минус — сдохшую детальку в сервисе под лаком искать и менять вряд ли будут, менять придется всю плату в сборе, а это гораздо дороже.![]()
Вот ниже составил список из достоинств и недостатков каждой модели питания, если есть что добавить – пишите в комментариях к статье.
Инверторный блок питания
Достоинства:
- Может работать при пониженном напряжении.
- Более легкий.
- Электронное управление значительно облегчает работу сварщика.
- Идеальный вариант для начинающих.
- Высокая ПВ (продолжительность непрерывного включения 60%)
Недостатки:
- Высокая стоимость.
- Не высокая надежность.
- Не любит пыль и влагу.
- Иногда весьма дорогой ремонт.
Трансформаторный блок питания
Достоинства:
- Надежный, практически нечему ломаться.
- Даже если что-то сломается легко починить.
Недостатки:
- Большой вес, громоздкий.
- Проводка должна держать ток от 16 до 25 Ампер.
- Низкая ПВ (продолжительность непрерывного включения)
- Высокий ток ХХ
- Низкий КПД
Перелопатив кучу сайтов, форумов, отзывов и другой полезной информации по выбору того или иного полуавтомата и в итоге получается такая картина:
- Если выбирать инвертор, то только известных производителей с широкой сетью сервисных центров в вашем регионе.
 Если таковых нет, то выбор в пользу трансформатора очевиден.
Если таковых нет, то выбор в пользу трансформатора очевиден. - Если в вашем гараже нет проблем с напряжением, хорошая электропроводка и есть место, куда поставить большой трансформатор, то выбор за ним.
- Если вы только начинаете свой путь в сварке, то начать, конечно, проще с инвертора, но учтите, что потом работать на трансформаторном полуавтомате вам и не захочется и вряд ли хорошо получится.
- Выбирая конкретную модель аппарата, «покурите» специализированные форумы (на один такой ссылка внизу статьи), там часто «тусят» спецы, зарабатывающие на ремонте сварочников. У них можно получить консультацию по конкретной модели или прочитать уже написанную.
И несколько простых советов по уходу за инвертором, если вы выбрали его:
- Известно, что пыль, особенно токопроводящая является злейшим врагом инвертора, поэтому регулярно, сняв крышку, продувайте его от пыли. Если аппарат отдыхает, пока вы работаете, например, со шпатлевкой, то накрывайте его пластиковым ящиком или хотя бы укрывайте его пленкой, например пакетом для хранения колес.
- Как и вся электроника, инверторные блоки питания боятся влаги. Поэтому, придя в гараж зимой и включив быстрое отопление, дайте время и аппарату нагреться, не включайте его сразу в работу, внутри него может сконденсироваться влага и вызвать замыкание.

Несомненно, прогресс идет вперед, в итоге трансформаторные блоки питания в сварочных аппаратах уйдут в прошлое. Инверторы станут дешевле, надежнее и работа выполняемая таким сварочным аппаратом будет превосходить все ожидания.
Уже не редкость когда у продвинутого сварщика в гараже можно найти последний писк разработчиков сварочного оборудования – не дешёвый инверторный универсал, который может выполнять сразу три вида работ, ему по зубам сварка электродами MMA, аргоновая TIG и на закуску MIG/MAG.
Большинство людей, вероятно, слышали о трансформаторах и знают, что они являются частью все еще очевидной, но все еще загадочной электрической сети, которая поставляет электроэнергию в дома, на предприятия и в любое другое место, где требуется «сок». Но энергосистема на самом деле является триумфом человеческой инженерии, без которой цивилизация была бы неузнаваема по сравнению с той, в которой вы живете сегодня. Трансформатор является ключевым элементом в управлении и доставке электроэнергии от точки, в которой оно производится на электростанциях, до момента, когда он не попадает в дом, офисное здание или другое конечное место назначения.
Подумайте о дамбе, сдерживающей миллионы галлонов воды, чтобы сформировать искусственное озеро. Поскольку река, питающая это озеро, не всегда несет в район одно и то же количество воды, а ее воды имеют тенденцию повышаться весной после таяния снега во многих районах и отливания летом в более сухое время, любая эффективная и безопасная плотина должна быть оснащен устройствами, которые обеспечивают более точное управление водой, чем просто прекращение ее протекания до тех пор, пока уровень не поднимется настолько, что вода просто начнет проливаться на нее. Примерно так работает трансформатор, за исключением того, что материал, который течет, это не вода, а электрический ток. Трансформаторы служат для управления уровнем напряжения, протекающего через любую точку энергосистемы (подробно описанную ниже), таким образом, чтобы сбалансировать эффективность передачи с базовой безопасностью. Очевидно, что как для потребителей, так и для владельцев электростанции и энергосистемы финансово и практически выгодно предотвращать потери электроэнергии между выходом электроэнергии из электростанции и ее попаданием в дома или в другие пункты назначения. С другой стороны, если величина напряжения, протекающего через типичный высоковольтный силовой провод, не уменьшится перед входом в ваш дом, это приведет к хаосу и катастрофе.
Напряжение является мерой разности электрических потенциалов. Ключевым словом здесь, на самом деле, является «разница». Причиной того, что электроны текут из одного места в другое, является разница в напряжении между двумя контрольными точками. Напряжение представляет собой объем работы, который потребуется на единицу заряда, чтобы переместить заряд против электрического поля из первой точки во вторую. Чтобы получить представление о масштабе, знайте, что провода передачи на большие расстояния обычно имеют напряжение от 155 000 до 765 000 вольт, тогда как напряжение на входе в дом обычно составляет 240 вольт.
В 1880-х годах поставщики электрических услуг использовали постоянный ток (DC). Это было чревато обязательствами, включая тот факт, что DC нельзя было использовать для освещения и было очень опасно, требуя толстых слоев изоляции. За это время изобретатель по имени Уильям Стэнли произвел индукционную катушку, устройство, способное создавать переменный ток (AC). В то время, когда Стэнли придумал это изобретение, физики знали о явлении переменного тока и его преимуществах с точки зрения энергоснабжения, но никто не смог придумать средства доставки переменного тока в больших масштабах. Индукционная катушка Стэнли будет служить шаблоном для всех будущих вариантов устройства. Стэнли чуть не стал адвокатом, прежде чем решил работать электриком. Он начал в Нью-Йорке, прежде чем переехать в Питтсбург, где он начал работать над своим трансформатором. Он построил первую муниципальную систему переменного тока в 1886 году в городе Грейт Баррингтон, штат Массачусетс. Может ли трансформатор увеличить напряжение? Трансформатор может как увеличивать (повышать), так и уменьшать (уменьшать) напряжение, передаваемое через силовые провода. Это примерно аналогично тому, как кровеносная система может увеличивать или уменьшать кровоснабжение определенных частей тела в зависимости от потребности. После того, как кровь («сила») покидает сердце («силовая установка»), чтобы достичь ряда точек ветвления, она может попасть в нижнюю часть тела вместо верхней части тела, а затем в правую ногу вместо слева, а затем к тельцу вместо бедра и т. д. Это определяется расширением или сужением кровеносных сосудов в органах и тканях-мишенях. Когда на электростанции вырабатывается электричество, трансформаторы повышают напряжение с нескольких тысяч до сотен тысяч в целях передачи на большие расстояния. Когда эти провода достигают точек, называемых силовыми подстанциями, трансформаторы снижают напряжение до 10000 вольт. Когда электричество покидает эти станции, что обычно происходит в разных направлениях, оно сталкивается с другими трансформаторами ближе к своей конечной точке в подразделениях, кварталах и отдельных домах. Эти трансформаторы снижают напряжение от менее 10000 вольт до значения около 240 — более чем в 1000 раз меньше, чем типичные максимальные уровни, наблюдаемые в проводах высокого напряжения большой длины.
Трансформаторы — это, конечно, только один компонент так называемой электросети, название системы проводов, коммутаторов и других устройств, которые производят, отправляют и контролируют электроэнергию от того места, где оно генерируется, до места, где оно в конечном итоге используется. Первым шагом в создании электрической энергии является вращение вала генератора. Прежде чем электричество покидает электростанцию, оно впервые сталкивается с трансформатором. Это единственная точка, в которой трансформаторы в электросети заметно повышают напряжение, а не снижают его. Этот шаг необходим, потому что электричество затем поступает на большие линии электропередачи по три комплекта, по одному на каждую фазу питания, и некоторым из них может потребоваться проехать до 300 миль или около того. В какой-то момент электричество попадает на электрическую подстанцию, где трансформаторы снижают напряжение до уровня, подходящего для более сдержанных линий электропередач, которые вы видите в микрорайонах или вдоль сельских дорог. Именно здесь происходит фаза распределения (в отличие от передачи) доставки электроэнергии, поскольку линии обычно покидают подстанции в нескольких направлениях, подобно ряду артерий, разветвляющихся от основного кровеносного сосуда в более или менее том же соединении. От подстанции электричество передается в микрорайоны и покидает местные линии электропередач (которые обычно находятся на «телефонных столбах») для входа в отдельные жилые дома. Какова функция трансформатора? Трансформаторы не только должны выполнять работу по управлению напряжением, но они также должны быть устойчивы к повреждениям, будь то стихийные бедствия, такие как ураганы или целенаправленные атаки, созданные человеком. Невозможно держать энергосистему вне досягаемости стихий или злоумышленников, но, тем не менее, энергосистема абсолютно необходима для современной жизни. Это сочетание уязвимости и необходимости привело к тому, что Департамент внутренней безопасности США заинтересовался крупнейшими трансформаторами в американской электросети, называемыми крупными силовыми трансформаторами, или LPT. Функционирование этих массивных трансформаторов, которые находятся на электростанциях и могут весить от 100 до 400 тонн и стоят миллионы долларов, имеет важное значение для поддержания повседневной жизни, поскольку выход из строя одного из них может привести к отключению электроэнергии на обширной территории , Это трансформаторы, которые резко повышают напряжение, прежде чем электричество попадает на междугородние провода высокого напряжения. По состоянию на 2012 год средний возраст LPT в США составлял около 40 лет. Некоторые из современных высоковольтных трансформаторов сверхвысокого напряжения (EHV) рассчитаны на 345 000 вольт, и спрос на трансформаторы растет как в США, так и во всем мире, что вынуждает правительство США искать способы замены существующих LPT по мере необходимости и разрабатывать новые по сравнительно низкой цене. Трансформатор — это большой квадратный магнит с отверстием посередине. Электричество поступает с одной стороны через провода, несколько раз обмотанные вокруг трансформатора, и уходит с противоположной стороны через провода, обернутые несколько раз вокруг трансформатора. Поступающее электричество индуцирует магнитное поле в трансформаторе, которое, в свою очередь, индуцирует электрическое поле в других проводах, которые затем отводят энергию от трансформатора. На уровне физики трансформатор работает, используя преимущества закона Фарадея, который гласит, что отношение напряжений двух катушек равно отношению числа витков в соответствующих катушках. |
 Таким образом, дамбы включают в себя все виды шлюзовых ворот и другие механизмы, которые определяют, сколько воды будет проходить на выходной стороне плотины, независимо от величины давления воды на входной стороне.
Таким образом, дамбы включают в себя все виды шлюзовых ворот и другие механизмы, которые определяют, сколько воды будет проходить на выходной стороне плотины, независимо от величины давления воды на входной стороне. Номенклатура может сбивать с толку, потому что многие студенты слышали термин «потенциальная энергия», что позволяет легко спутать напряжение с энергией. Фактически, напряжение — это электрическая потенциальная энергия на единицу заряда или джоули на кулон (Дж / с). Кулон является стандартной единицей электрического заряда в физике. Единственному электрону присваивают -1,609 × 10-19 кулонов, в то время как протон несет заряд, равный по величине, но противоположный по направлению (то есть положительный заряд).
Номенклатура может сбивать с толку, потому что многие студенты слышали термин «потенциальная энергия», что позволяет легко спутать напряжение с энергией. Фактически, напряжение — это электрическая потенциальная энергия на единицу заряда или джоули на кулон (Дж / с). Кулон является стандартной единицей электрического заряда в физике. Единственному электрону присваивают -1,609 × 10-19 кулонов, в то время как протон несет заряд, равный по величине, но противоположный по направлению (то есть положительный заряд). После рубежа веков его энергетическая компания была куплена General Electric.
После рубежа веков его энергетическая компания была куплена General Electric. Вы, наверное, видели эти подстанции и их трансформаторы среднего уровня в своих путешествиях; Трансформаторы обычно размещаются в коробках и выглядят как холодильники, установленные на обочинах дорог.
Вы, наверное, видели эти подстанции и их трансформаторы среднего уровня в своих путешествиях; Трансформаторы обычно размещаются в коробках и выглядят как холодильники, установленные на обочинах дорог. По состоянию на 2018 г. чаще всего это делается с использованием пара, выделяющегося при сжигании ископаемого топлива, такого как уголь, нефть или природный газ. Атомные электростанции и другие «чистые» генераторы энергии, такие как гидроэлектростанции и ветряные мельницы, также могут использовать или производить энергию, необходимую для работы генератора. В любом случае, электричество, которое вырабатывается на этих станциях, называется трехфазной. Это связано с тем, что эти генераторы переменного тока вырабатывают электричество, которое колеблется между установленным минимальным и максимальным уровнем напряжения, и каждая из трех фаз смещена на 120 градусов от тех, которые находятся впереди и позади него во времени. (Представьте, что вы идете взад и вперед по 12-метровой улице, в то время как двое других делают то же самое, совершая 24-метровую поездку в оба конца, за исключением того, что один из двух других людей всегда на 8 метров впереди вас, а другой на 8 метров позади вас. Иногда двое из вас будут идти в одном направлении, в то время как в другое время двое из вас будут идти в другом направлении, изменяя сумму ваших движений, но в предсказуемой форме.
По состоянию на 2018 г. чаще всего это делается с использованием пара, выделяющегося при сжигании ископаемого топлива, такого как уголь, нефть или природный газ. Атомные электростанции и другие «чистые» генераторы энергии, такие как гидроэлектростанции и ветряные мельницы, также могут использовать или производить энергию, необходимую для работы генератора. В любом случае, электричество, которое вырабатывается на этих станциях, называется трехфазной. Это связано с тем, что эти генераторы переменного тока вырабатывают электричество, которое колеблется между установленным минимальным и максимальным уровнем напряжения, и каждая из трех фаз смещена на 120 градусов от тех, которые находятся впереди и позади него во времени. (Представьте, что вы идете взад и вперед по 12-метровой улице, в то время как двое других делают то же самое, совершая 24-метровую поездку в оба конца, за исключением того, что один из двух других людей всегда на 8 метров впереди вас, а другой на 8 метров позади вас. Иногда двое из вас будут идти в одном направлении, в то время как в другое время двое из вас будут идти в другом направлении, изменяя сумму ваших движений, но в предсказуемой форме. работает трехфазная сеть переменного тока.)
работает трехфазная сеть переменного тока.) Меньшие трансформаторы (многие из которых выглядят как маленькие металлические мусорные баки) снижают напряжение примерно до 240 вольт, чтобы оно могло попасть в дома без большого риска возникновения пожара или другого серьезного несчастного случая.
Меньшие трансформаторы (многие из которых выглядят как маленькие металлические мусорные баки) снижают напряжение примерно до 240 вольт, чтобы оно могло попасть в дома без большого риска возникновения пожара или другого серьезного несчастного случая.
Блог сварщика
Альтернативные источники энергии
2022-02-07
…
Владимир Будянов. Альтернативные технологии, Россия и Новый мировой порядок.
2022-02-03
Доктора наук Сергей Салль, Анатолий Конев, Валерий Дудышев (акад. Российской экологической академии) и ряд других учёных работают над созданием эффективных технологий, направленных на решение ключевых проблем человечества. Но на их пути стоит Всемирное мировое правительство… Передовые русские учёные обоснованно связывают современную мировую политику, направленную на установление Нового мирового порядка на основе всесилия «золотого тельца», с повсеместным обязательным подавлением новых технологий, в первую очередь энергетических и…
Альтернативная энергия своими руками: обзор лучших возобновляемых источников электричества
2017-12-21
Сегодня всем известно, что запасы углеводородов на Земле имеют свой предел. С каждым годом все труднее становится добывать нефть и газ из недр. Кроме того, их сжигание наносит непоправимый ущерб экологии нашей планеты. Несмотря на то, что технологии производства возобновляемой энергии сегодня очень эффективны, государства не спешат отказываться от сжигания топлива. При этом, цены на энергоносители растут с каждым годом, заставляя простых граждан все больше и больше раскошеливаться. В связи с этим, производство альтернативной энергии сегодня…
С каждым годом все труднее становится добывать нефть и газ из недр. Кроме того, их сжигание наносит непоправимый ущерб экологии нашей планеты. Несмотря на то, что технологии производства возобновляемой энергии сегодня очень эффективны, государства не спешат отказываться от сжигания топлива. При этом, цены на энергоносители растут с каждым годом, заставляя простых граждан все больше и больше раскошеливаться. В связи с этим, производство альтернативной энергии сегодня…
Альтернативные виды энергии. Обзор источников электичесива
2017-12-21
Ограниченные запасы ископаемого топлива и глобальное загрязнение окружающей среды заставило человечество искать возобновляемые альтернативные источники такой энергии, чтобы вред от ее переработки был минимальным при приемлемых показателях себестоимости производства, переработки и транспортировки энергоресурсов.
Современные технологии позволяют использовать имеющиеся альтернативные энергетические ресурсы, как в масштабе целой планеты, так и в пределах энергосети квартиры или частного дома. Буйное развитие жизни на протяжении нескольких…
Буйное развитие жизни на протяжении нескольких…
Альтернативные технологии — Россия и Новый мировой порядок.
2017-12-21
http://www.dal.by/news/89/28-08-12-25/ Альтернативные технологии, Россия и Новый мировой порядок Доктора наук Сергей Салль, Анатолий Конев, Валерий Дудышев (акад. Российской экологической академии) и ряд других учёных работают над созданием эффективных технологий, направленных на решение ключевых проблем человечества. Но на их пути стоит Всемирное мировое правительство… Передовые русские учёные обоснованно связывают современную мировую политику, направленную на установление Нового мирового порядка на основе всесилия «золотого…
Аккумуляторы для солнечных батарей
2017-12-21
Аккумуляторы для солнечных батарей — это буфер, обеспечивающий накопление энергии посредством обратимых химических реакций, благодаря чему гарантируется работа в циклическом режиме. В солнечных системах используются аккумуляторные батареи герметичные и малообслуживаемые , а также Никель-солевые накопители энергии которые обладают большим ресурсом и предназначены специально для циклической работы. В настоящий момент самые востребованные свинцово-кислотные аккумуляторы для солнечных батарей , т.к это самый доступный класс накопителей…
В солнечных системах используются аккумуляторные батареи герметичные и малообслуживаемые , а также Никель-солевые накопители энергии которые обладают большим ресурсом и предназначены специально для циклической работы. В настоящий момент самые востребованные свинцово-кислотные аккумуляторы для солнечных батарей , т.к это самый доступный класс накопителей…
Аккумуляторы для рынка возобновляемых источников энергии
2017-12-21
Журнал РАДИОЛОЦМАН, июнь 2014
Bruce Dorminey
Renewable Energy World Magazine
Как развивающиеся, так и развитые страны мира имеют веские основания задуматься об использовании аккумуляторных технологий. И вот почему.
С тех дней, когда ваш дедушка вынужден был периодически открывать капот, чтобы добавить воды в свинцово-кислотную батарею, технология аккумуляторов прошла долгий путь.
Всего десять лет назад идея, что блоки аккумуляторов скоро будут «сглаживать потоки энергии», текущей от ветряных и солнечных ферм в электрические сети, казалась почти фантастической. …
…
Безтопливные генераторы — уже реальность (+видео) — Форум Izhcommunal.ru
2017-06-30
Гидроэнергоблок для безплотинных ГЭС Изобретатель Ленёв Николай Иванович. Патент №2166664 В изобретении предлагается оригинальный, ранее не использовавшийся ни в одной из существующих конструкций, способ использования энергии как водного потока любого вида (рек, ручьёв, приливов, морской волны и т.д.) так и движения воздушных масс. При этом используется естественный поток, без предварительного преобразования (строительства дамб, каналов, напорных труб). Данный способ отъёма мощности водного потока является наиболее выгодным и с экологической…
Альтернативная энергетика
2017-06-22
содержание презентации «Альтернативная энергетика.ppt»
№
Слайд
Текст 1 Альтернативная энергия
в помощь Экологии и Энергосбережению Псков 2010г.
Автономная некоммерческая организация Cоциально-консультационный центр «ПсковРегионИнфо» Альтернативная Энергия 2 Возобновляемые источники энергии
Автономная некоммерческая организация Cоциально-консультационный центр «ПсковРегионИнфо» Альтернативная Энергия.![]() Возобновляемые источники энергии – это не альтернатива существующей энергетике, а ее будущее, и вопрос лишь в том, когда…
Возобновляемые источники энергии – это не альтернатива существующей энергетике, а ее будущее, и вопрос лишь в том, когда…
Трансформатор ТС-180 в блоке питания трансивера — 6 Февраля 2013 — Блог
Трансформатор ТС-180 в блоке питания трансивера.
АВТОР(схема): А. Перуцкий (ER2OD)
(статья): С. Струганов (UA9XСN)
Поводом для написания настоящей статьи послужила публикация [1], в которой автор рекомендовал для питания лампового УМЧЗ использовать силовой трансформатор ТС-180. Действительно, этот трансформатор я тоже использовал для питания усилителя на лампах 6П41С [2], а также при ремонте ламповых радиоприемников и радиол с двухтактным оконечным каскадом взамен сгоревших «штатных» силовых трансформаторов.
Я хочу поделиться опытом изготовления блока питания трансивера с оконечным гибридным каскадом на базе силового трансформатора типа ТС-180 (ТС-180-2) рис.![]() 1. Паспортные данные указанного трансформатора приведены, например, в [3]. Мне встречались трансформаторы типа ТС-180 с небольшими различиями в количестве витков в обмотках, в том числе и трансформаторы с обмотками 2×127В (с отводами по 110 В — лепестки-выводы 2 и 2′), т.е. у них задействованы и лепестки-выводы 3 и 3′.
1. Паспортные данные указанного трансформатора приведены, например, в [3]. Мне встречались трансформаторы типа ТС-180 с небольшими различиями в количестве витков в обмотках, в том числе и трансформаторы с обмотками 2×127В (с отводами по 110 В — лепестки-выводы 2 и 2′), т.е. у них задействованы и лепестки-выводы 3 и 3′.
В схеме гибридного оконечного каскада [4], где применены лампа 6П45С и транзистор КТ904А, кроме напряжений анода, экранной сетки и накала лампы, необходим источник отрицательного напряжения (около 60 В) для запирания лампы в режиме приема. Конечно, существуют и другие варианты гибридного каскада на лампе 6П45С, в которых не требуется источник запирающего напряжения, но необходимо применять напряжение +24В для схемы управления.
В любом случае, необходима отдельная обмотка на силовом трансформаторе. На одной из двух катушек силового трансформатора ТС-180 имеется свободное место, где можно разместить недостающую обмотку (это видно «визуально», а также при прощупывании катушки).![]()
Вот на этом свободном месте можно намотать дополнительную обмотку. Эта процедура несложная, и производится следующим образом. Временно распаиваются перемычки между обмотками катушек, и снимается стяжное крепление трансформатора (полосы, гайки и т.д.). Перед этим обязательно требуется пометить каким-либо образом расположение катушек и кернов трансформатора, с тем чтобы при обратной сборке все детали «легли» на свое место.
Это исключит (или уменьшит до минимума) «гудение» трансформатора под напряжением. После этого легкими, но резкими ударами молотка через дощечку (обязательно!) «срывают» половинки керна с клея и осторожно снимают ту половину керна, где имеется свободное место на катушке. Затем снимаем с керна только эту катушку, временно аккуратно удаляем наружную бумагу с надписями и номерами лепестков (при обратной сборке восстанавливаем ее на свое место).
Далее снимаем защитное бумажное покрытие и открываем доступ к обмоткам. На части свободного места и на обмотке 6,4В с током 0,3 А наматываем 80…90 витков провода типа ПЭВ-1 или ПЭВ-2 диаметром 0,25…0,31 мм (проложив перед намоткой и после нее один-два слоя изоляции из бумаги).
На части свободного места и на обмотке 6,4В с током 0,3 А наматываем 80…90 витков провода типа ПЭВ-1 или ПЭВ-2 диаметром 0,25…0,31 мм (проложив перед намоткой и после нее один-два слоя изоляции из бумаги).
Выводы этой обмотки лучше делать многожильным проводом типа МГТФ длиной 15…20 см. Для выводов в боковых щечках катушки шилом или электродрелью делаем два отверстия (если имеющиеся не подходят по месту), стараясь не повредить обмотки катушки. После этого на клею заделываем бумажную изоляцию, затем общую изоляцию катушки и в конце — наружную бумажную обертку с надписями, совместив номера лепестков. После этой операции производится обратная сборка катушки, керна, затягивание арматуры трансформатора.
Я не применял дополнительного проклеивания кернов. При испытании готового трансформатора под напряжением при касании корпуса трансивера ощущалась едва заметная вибрация. Нагрева трансформатора не наблюдалось. Переменное напряжение дополнительной обмотки (она обозначена на схеме блока питания цифрами 13-14) должно составлять 23. ..25 В.
..25 В.
Применяя схему выпрямителя с удвоением напряжения, получим необходимые -60…-70 В постоянного тока. Собственно, в схеме блока питания, приведенной на рисунке, применены известные схемные и конструктивные решения, и особых пояснений не требуется, в том числе и по замене деталей (транзисторов, конденсаторов и т.д.).
Для получения анодного напряжения (580…600 В) обмотки трансформатора 5-6, 7-8, 5′-6′ и 7′-8′ включаются последовательно-согласованно. Для напряжения +12,5В применяется такое же включение обмоток 9-10 и 11-12. В режиме «холостого хода» переменное напряжение на обмотках составляет около 210В (для анода) и 14В (для источника +12,5 В). Из возможных вариантов включения обмоток один указан на схеме блока питания.
При рассмотрении схем выпрямителей видно, что корпуса оксидных конденсаторов С2, С6 и С8 изолированы от корпуса (шасси) трансивера. Коллектор транзистора VT2, наоборот, соединен с корпусом, что очень удобно конструктивно.
При установке трансформатора в корпусе трансивера, с целью соблюдения правил техники безопасности, очень желательно выводы, к которым подводится напряжение сети переменного тока и с которых выводится анодное напряжение, закрыть пластинами-накладками из стеклотекстолита или гетинакса.
Иллюстрированное руководство по трансформаторам — пошаговое объяснение | Майкл Фи
Трансформеры берут штурмом мир обработки естественного языка. Эти невероятные модели бьют многочисленные рекорды НЛП и продвигают искусство. Они используются во многих приложениях, таких как машинный перевод, диалоговые чат-боты и даже для повышения эффективности поисковых систем. Трансформеры сейчас в моде в глубоком обучении, но как они работают? Почему они превзошли предыдущего короля задач последовательности, таких как рекуррентные нейронные сети, GRU и LSTM? Вы, наверное, слышали о различных известных моделях трансформаторов, таких как BERT, GPT и GPT2. В этом посте мы сосредоточимся на одной статье, с которой все началось: «Внимание — это все, что вам нужно».
В этом посте мы сосредоточимся на одной статье, с которой все началось: «Внимание — это все, что вам нужно».
Перейдите по ссылке ниже, если хотите посмотреть видеоверсию.
Чтобы понять трансформаторы, мы должны сначала понять механизм внимания. Механизм Attention позволяет преобразователям иметь чрезвычайно долговременную память. Модель преобразователя может «присутствовать» или «сосредоточиться» на всех предыдущих сгенерированных токенах.
Давайте рассмотрим пример. Скажем, мы хотим написать короткий научно-фантастический роман с генеративным преобразователем.Используя приложение Write With Transformer от Hugging Face, мы можем сделать именно это. Мы загрузим модель нашими входными данными, а модель сгенерирует все остальное.
Наш ввод: «Как инопланетяне проникли на нашу планету».
Выход трансформатора: «и начали колонизировать Землю, определенная группа инопланетян начала манипулировать нашим обществом через свое влияние на определенное количество элиты, чтобы удерживать и железной хваткой население».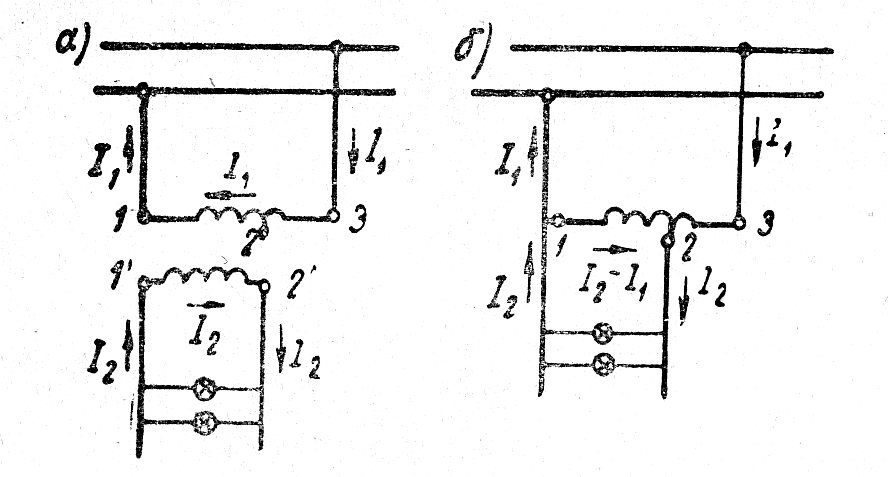
Итак, история немного темная, но интересно то, как модель ее сгенерировала.Поскольку модель генерирует текст слово за словом, она может «присутствовать» или «сосредоточиться» на словах, которые имеют отношение к сгенерированному слову. Способность знать, какие слова следует учитывать, также изучается во время обучения с помощью обратного распространения ошибки.
Механизм внимания фокусируется на разных токенах при генерации слов 1 на 1 Рекуррентные нейронные сети (RNN) также способны просматривать предыдущие входные данные. Но сила механизма внимания в том, что он не страдает от кратковременной памяти. RNN имеют более короткое окно для ссылок, поэтому, когда история становится длиннее, RNN не может получить доступ к словам, сгенерированным ранее в последовательности.Это по-прежнему верно для сетей Gated Recurrent Units (GRU) и Long-Short Term Memory (LSTM), хотя они имеют большую емкость для достижения долговременной памяти, поэтому имеют более длинное окно для ссылок. Теоретически механизм внимания и при наличии достаточных вычислительных ресурсов имеет бесконечное окно для ссылок, поэтому он способен использовать весь контекст истории при создании текста.
Теоретически механизм внимания и при наличии достаточных вычислительных ресурсов имеет бесконечное окно для ссылок, поэтому он способен использовать весь контекст истории при создании текста.
На высоком уровне кодер отображает входную последовательность в абстрактное непрерывное представление, которое содержит всю изученную информацию об этом входе. Затем декодер берет это непрерывное представление и шаг за шагом генерирует один выходной сигнал, одновременно получая предыдущий выходной сигнал.
Давайте рассмотрим пример. В статье модель Transformer применялась к задаче нейронного машинного перевода. В этом посте мы покажем, как это будет работать для разговорного чат-бота.
Наш ввод: «Привет, как дела»
Выход трансформатора: «Я в порядке»
Первый шаг — это ввод ввода в слой встраивания слов. Слой встраивания слов можно рассматривать как справочную таблицу для получения изученного векторного представления каждого слова. Нейронные сети обучаются с помощью чисел, поэтому каждое слово сопоставляется с вектором с непрерывными значениями для представления этого слова.
Слой встраивания слов можно рассматривать как справочную таблицу для получения изученного векторного представления каждого слова. Нейронные сети обучаются с помощью чисел, поэтому каждое слово сопоставляется с вектором с непрерывными значениями для представления этого слова.
Следующим шагом является вставка позиционной информации во вложения.Поскольку кодер-трансформер не имеет повторения, как рекуррентные нейронные сети, мы должны добавить некоторую информацию о позициях во входные вложения. Это делается с помощью позиционного кодирования. Авторы придумали хитрый трюк, используя функции синуса и косинуса.
Мы не будем вдаваться в математические подробности позиционного кодирования, но вот основы. Для каждого нечетного индекса входного вектора создайте вектор с помощью функции cos. Для каждого четного индекса создайте вектор с помощью функции sin.Затем добавьте эти векторы к соответствующим входным вложениям.![]() Это успешно дает сети информацию о положении каждого вектора. Функции синуса и косинуса были выбраны в тандеме, потому что они обладают линейными свойствами, которым модель может легко научиться уделять внимание.
Это успешно дает сети информацию о положении каждого вектора. Функции синуса и косинуса были выбраны в тандеме, потому что они обладают линейными свойствами, которым модель может легко научиться уделять внимание.
Теперь у нас есть слой кодировщика. Задача слоев кодировщика заключается в отображении всех входных последовательностей в абстрактное непрерывное представление, которое содержит изученную информацию для всей этой последовательности. Он содержит 2 подмодуля, многоглавое внимание, за которым следует полностью подключенная сеть.Также существуют остаточные соединения вокруг каждого из двух подслоев, за которыми следует нормализация уровня.
Подмодули уровня кодировщикаЧтобы разобрать это, давайте сначала рассмотрим многоголовый модуль внимания.
Многоголовое внимание в кодировщике применяет особый механизм внимания, называемый самостоятельным вниманием. Самостоятельное внимание позволяет моделям связывать каждое слово во входных данных с другими словами. Так что в нашем примере вполне возможно, что наша модель может научиться ассоциировать слово «ты» с «как» и «есть».Также возможно, что модель узнает, что слова, структурированные по этому шаблону, обычно являются вопросом, поэтому отвечайте соответствующим образом.
Так что в нашем примере вполне возможно, что наша модель может научиться ассоциировать слово «ты» с «как» и «есть».Также возможно, что модель узнает, что слова, структурированные по этому шаблону, обычно являются вопросом, поэтому отвечайте соответствующим образом.
Векторы запроса, ключа и значения
Чтобы добиться самоконтроля, мы передаем входные данные в 3 отдельных полностью связанных слоя для создания векторов запроса, ключа и значения.
Что это за векторы? Я нашел хорошее объяснение по обмену стеками, в котором говорится….
«Концепция ключа и значения запроса пришла из поисковых систем. Например, когда вы вводите запрос для поиска какого-либо видео на Youtube, поисковая система сопоставит ваш запрос с набором ключей (название видео, описание и т.
 д.), связанных с видео-кандидаты в базу данных, а затем представить вам наиболее подходящие видео ( значений ).
д.), связанных с видео-кандидаты в базу данных, а затем представить вам наиболее подходящие видео ( значений ). Скалярное произведение запроса и ключа
После подачи запроса, ключа и вектора значений через линейный слой запросы и ключи подвергаются умножению матрицы скалярного произведения для получения матрицы оценок.
Скалярное произведение запроса и ключаМатрица оценок определяет, сколько внимания следует уделять слову другим словам. Таким образом, каждое слово будет иметь оценку, соответствующую другим словам на временном шаге. Чем выше оценка, тем больше внимания. Вот как запросы сопоставляются с ключами.
Оценка внимания по скалярному произведению.Уменьшение оценок внимания
Затем оценки уменьшаются путем деления на квадратный корень из измерения запроса и ключа.Это сделано для того, чтобы обеспечить более стабильные градиенты, поскольку умножение значений может привести к взрывному эффекту.
Softmax масштабированных оценок
Затем вы берете softmax масштабированных оценок, чтобы получить веса внимания, что дает вам значения вероятности от 0 до 1. Выполняя softmax, более высокие оценки повышаются, а более низкие баллы вызывают депрессию. Это позволяет модели быть более уверенной в том, какие слова следует учитывать.
Взятие softmax масштабированных оценок для получения значений вероятностиУмножение выходных данных Softmax на вектор значений
Затем вы берете веса внимания и умножаете их на вектор значений, чтобы получить выходной вектор.Более высокие баллы softmax сохранят ценность слов, которые выучивает модель, более важными. Более низкие баллы заглушат нерелевантные слова. Затем вы передаете результат этого в линейный слой для обработки.
Чтобы сделать это вычислением внимания с несколькими головками, вам нужно разделить запрос, ключ и значение на N векторов, прежде чем применять само-внимание. Затем расщепленные векторы проходят через процесс само-внимания по отдельности. Каждый процесс само-внимания называется головой. Каждая головка создает выходной вектор, который объединяется в один вектор перед прохождением через последний линейный слой.Теоретически каждая головка будет изучать что-то свое, что даст модели кодировщика больше возможностей представления.
Затем расщепленные векторы проходят через процесс само-внимания по отдельности. Каждый процесс само-внимания называется головой. Каждая головка создает выходной вектор, который объединяется в один вектор перед прохождением через последний линейный слой.Теоретически каждая головка будет изучать что-то свое, что даст модели кодировщика больше возможностей представления.
Подводя итог, можно сказать, что многоголовое внимание — это модуль в сети преобразователя, который вычисляет весовые коэффициенты внимания для входных данных и создает выходной вектор с закодированной информацией о том, как каждое слово должно сопровождать все остальные слова в последовательности.
Выходной вектор многоголового внимания добавляется к исходному позиционному встраиванию входных данных.Это называется остаточным соединением. Выход остаточного соединения проходит нормализацию слоя.
Нормализованный остаточный вывод проецируется через точечную сеть прямой связи для дальнейшей обработки. Сеть точечной прямой связи представляет собой пару линейных слоев с активацией ReLU между ними. Выход этого затем снова добавляется к входу сети с точечной прямой связью и дополнительно нормализуется.
Остаточная связь входа и выхода слоя точечной прямой связи.Остаточные соединения помогают сети обучаться, позволяя градиентам проходить через сети напрямую. Нормализация слоев используется для стабилизации сети, что приводит к существенному сокращению необходимого времени обучения. Слой точечной прямой связи используется для проецирования результатов внимания, что потенциально дает более богатое представление.
Это завершает слой кодировщика. Все эти операции предназначены для кодирования ввода в непрерывное представление с информацией о внимании. Это поможет декодеру сосредоточиться на соответствующих словах во входных данных в процессе декодирования. Вы можете сложить кодировщик N раз для дальнейшего кодирования информации, где каждый уровень имеет возможность изучить различные представления внимания, что потенциально повышает прогностическую силу сети преобразователя.
Это поможет декодеру сосредоточиться на соответствующих словах во входных данных в процессе декодирования. Вы можете сложить кодировщик N раз для дальнейшего кодирования информации, где каждый уровень имеет возможность изучить различные представления внимания, что потенциально повышает прогностическую силу сети преобразователя.
Задача декодера — генерировать текстовые последовательности. Декодер имеет такой же подуровень, что и кодер. он имеет два уровня внимания с несколькими головками, уровень точечной прямой связи и остаточные соединения, а также нормализацию уровня после каждого подуровня.Эти подуровни ведут себя аналогично слоям в кодировщике, но каждый многоголовый уровень внимания выполняет другую работу. Декодер ограничен линейным слоем, который действует как классификатор, и softmax для получения вероятностей слов.
Уровень декодера. Ссылка на эту диаграмму при чтении. Декодер является авторегрессивным, он начинается с начального маркера и принимает в качестве входных данных список предыдущих выходных данных, а также выходные данные кодировщика, которые содержат информацию о внимании из входных данных.![]() Декодер останавливает декодирование, когда генерирует токен в качестве вывода.
Декодер останавливает декодирование, когда генерирует токен в качестве вывода.
Давайте пройдемся по шагам декодирования.
Начало декодера очень похоже на кодировщик. Входные данные проходят через слой внедрения и слой позиционного кодирования для получения позиционных вложений. Позиционные вложения передаются в первый уровень внимания с несколькими головками, который вычисляет оценки внимания для ввода декодера.
Этот слой внимания с несколькими головками работает несколько иначе. Поскольку декодер является авторегрессивным и генерирует последовательность слово за словом, вам необходимо предотвратить его преобразование в будущие токены. Например, при подсчете оценки внимания к слову «ам» у вас не должно быть доступа к слову «отлично», потому что это слово является будущим словом, которое было сгенерировано позже. Слово «есть» должно иметь доступ только к себе и к словам перед ним. Это верно для всех других слов, где они могут обращать внимание только на предыдущие слова.
Слово «есть» должно иметь доступ только к себе и к словам перед ним. Это верно для всех других слов, где они могут обращать внимание только на предыдущие слова.
Нам нужен метод, предотвращающий вычисление показателей внимания для будущих слов. Этот метод называется маскировкой. Чтобы декодер не просматривал будущие токены, вы применяете маску просмотра вперед. Маска добавляется перед вычислением softmax и после масштабирования баллов. Давайте посмотрим, как это работает.
Упреждающая маска
Маска представляет собой матрицу того же размера, что и оценки внимания, заполненные значениями нулей и минус бесконечности.Когда вы добавляете маску к масштабированным оценкам внимания, вы получаете матрицу оценок, в которой верхний правый треугольник заполнен отрицательными бесконечностями.
Причина использования маски в том, что как только вы берете softmax замаскированных оценок, отрицательные бесконечности обнуляются, оставляя нулевые оценки внимания для будущих токенов. Как вы можете видеть на рисунке ниже, оценка внимания для «am» имеет значения для себя и всех слов перед ним, но равна нулю для слова «fine».По сути, это говорит модели не обращать внимания на эти слова.
Эта маскировка является единственным отличием в том, как рассчитываются оценки внимания в первом многоголовом слое внимания. Этот слой по-прежнему имеет несколько головок, к которым применяется маска, прежде чем они будут объединены и пропущены через линейный слой для дальнейшей обработки. Выход первого многоголового внимания представляет собой замаскированный выходной вектор с информацией о том, как модель должна реагировать на ввод декодера.
Многоголовое внимание с маскировкой Второй слой многоголового внимания. Для этого уровня выходные данные кодировщика — это запросы и ключи, а выходные данные первого многоголового уровня внимания — значения. Этот процесс сопоставляет ввод кодировщика с вводом декодера, позволяя декодеру решить, какой ввод кодировщика имеет значение, на котором следует сосредоточить внимание. Выход второго многоголового внимания проходит через слой точечной прямой связи для дальнейшей обработки.
Для этого уровня выходные данные кодировщика — это запросы и ключи, а выходные данные первого многоголового уровня внимания — значения. Этот процесс сопоставляет ввод кодировщика с вводом декодера, позволяя декодеру решить, какой ввод кодировщика имеет значение, на котором следует сосредоточить внимание. Выход второго многоголового внимания проходит через слой точечной прямой связи для дальнейшей обработки.
Выходные данные последнего слоя точечной прямой связи проходят через последний линейный слой, который действует как классификатор.Классификатор такой же большой, как и количество классов, которые у вас есть. Например, если у вас есть 10 000 классов для 10 000 слов, вывод этого классификатора будет иметь размер 10 000. Затем выходные данные классификатора передаются на слой softmax, который будет давать оценки вероятности от 0 до 1. Мы берем индекс наивысшей оценки вероятности, и он равен нашему предсказанному слову.
Линейный классификатор с Softmax для получения выходных вероятностей Затем декодер берет выходные данные, добавляет их в список входных данных декодера и снова продолжает декодирование, пока не будет предсказан токен. В нашем случае предсказание с наибольшей вероятностью — это окончательный класс, который назначается конечному токену.
В нашем случае предсказание с наибольшей вероятностью — это окончательный класс, который назначается конечному токену.
Декодер также может быть сложен в N слоев, каждый слой получает входные данные от кодировщика и слоев перед ним. Накладывая слои друг на друга, модель может научиться извлекать и сосредотачиваться на различных комбинациях внимания со своих головок внимания, потенциально повышая свою предсказательную силу.
Многоуровневый кодировщик и декодер Вот и все! Это механика трансформеров.Трансформеры используют силу механизма внимания, чтобы делать более точные прогнозы. Рекуррентные нейронные сети пытаются достичь подобных целей, но потому что они страдают от кратковременной памяти. Трансформеры могут быть лучше, особенно если вы хотите кодировать или генерировать длинные последовательности. Благодаря архитектуре преобразователя индустрия обработки естественного языка может достичь беспрецедентных результатов.
Посетите веб-сайт michaelphi.com, чтобы найти больше подобного контента.
избранных – БЛОГ ИНТЕЛЛЕКТУАЛЬНОГО ТРАНСФОРМАТОРА
Приглашенный блоггер Трейси Хопкинс, старший консультант по обучению и образованию, SDMyers Какой бы стиль обучения персонала ни применялся в вашей организации — обучение на рабочем месте, профессиональная школа, курсы повышения квалификации по оборудованию, стажировки или внешнее техническое обучение — есть одно. это может повысить эффективность этого обучения и значительно увеличить удержание: непрерывность.Когда непрерывное обучение персонала становится приоритетным, расширяется и укрепляется, появляются программы обеспечения надежности. Недостаточно провести обучение команд… продолжить чтение Непрерывное обучение укрепляет вашу программу надежности активов
Приглашенный блоггер Уэсли Суплит, менеджер по продукту, SDMyers После первого года обучения в колледже я обнаружил, что моя любимая учебная программа – экономика.![]() Это удивило моих друзей и семью, потому что эта дисциплина известна своим сухим содержанием и сложными математическими понятиями.Однако у меня был совершенно другой и вдохновляющий опыт. Курс и, действительно, мой профессор открыли мне глаза на красоту наблюдения за тем, как люди… Читать далее 4 простых шага для онлайн-мониторинга трансформатора
Это удивило моих друзей и семью, потому что эта дисциплина известна своим сухим содержанием и сложными математическими понятиями.Однако у меня был совершенно другой и вдохновляющий опыт. Курс и, действительно, мой профессор открыли мне глаза на красоту наблюдения за тем, как люди… Читать далее 4 простых шага для онлайн-мониторинга трансформатора
В SDMyers мы не можем не подчеркнуть важность безопасности при тестировании высоковольтного электроэнергетического оборудования. Наши партнеры в IRISS разделяют наше стремление к безопасности обслуживающего персонала на местах, в том числе наших собственных мобильных специалистов по диагностике.Мы надеемся, что этот гостевой блог от них является образовательным. Если вы найдете в этом ценность, пожалуйста, оставьте нам комментарий. И, если вам понравилась эта статья, то… Продолжить чтение То, что вы можете, не означает, что вы должны это делать!
Страховые компании требуют, чтобы промышленные предприятия проверили свои системы электроснабжения, в том числе трансформаторы. Однако часто руководство не знает, что делать с результатами тестов, кроме предоставления их страховой компании.Результаты заносятся в папку, а существенная часть плана обеспечения надежности компании упускается из виду. Алан Росс беседует с Тони Дотсоном из WestRock о том, как бумажная компания начала использовать эти данные… продолжить чтение Подкаст Intelligent Transformer № 3: Алан Росс и Тони Дотсон
Однако часто руководство не знает, что делать с результатами тестов, кроме предоставления их страховой компании.Результаты заносятся в папку, а существенная часть плана обеспечения надежности компании упускается из виду. Алан Росс беседует с Тони Дотсоном из WestRock о том, как бумажная компания начала использовать эти данные… продолжить чтение Подкаст Intelligent Transformer № 3: Алан Росс и Тони Дотсон
В мае мы спонсировали саммит, на который собрались в Хьюстон лидеры надежности электроэнергетики со всей страны, чтобы обсудить разрыв в надежности. У меня было несколько недель, чтобы подумать об этом событии, и я хочу поделиться этими мыслями с вами.Если SDMyers была матерью Саммита по надежности электроснабжения (EPRS), то я чувствую себя акушеркой. … продолжить чтение Требуется деревня
Мне пришлось многому научиться, чтобы стать лидером по надежности трансформаторов. У меня есть инженерное образование, а также опыт обслуживания и испытаний трансформаторов, но чтобы стать практиком, которым я хотел быть, мне нужно было получить образование. Я искал знания о надежности. Я нашел большую часть этих знаний благодаря чтению и исследованиям.Это началось с поиска в Google и статей в Википедии, и в конечном итоге привело к … Продолжить чтение Почему никто не говорит об этом?
Я искал знания о надежности. Я нашел большую часть этих знаний благодаря чтению и исследованиям.Это началось с поиска в Google и статей в Википедии, и в конечном итоге привело к … Продолжить чтение Почему никто не говорит об этом?
Как только страус засовывает голову в песок, опасность, с которой он может столкнуться, исчезает, верно? Конечно, нет! Я считаю, что мы живем — относительно надежности электрической системы — с тем, что мы называем эффектом страуса. У большинства из нас голова застряла в песке. Но знаете что? Песок осыпается, и страус начинает что-то видеть; … продолжить чтение Эффект страуса
Когда вы начинаете составлять программу рисков и надежности для высоковольтного электрооборудования, в первую очередь трансформаторов, вам придется пройти через культурные изменения.Я видел это неоднократно, как на рынке промышленных товаров, так и на рынке коммунальных услуг. Это никогда не решение одного человека. Шаг № 1: Лидер в области надежности Как лидер в области надежности мы обычно можем наложить вето на любой проект, но чаще всего мы не можем сказать… продолжить чтение 5 шагов к обеспечению приверженности программе обеспечения надежности трансформаторов
Если рассматривать техническое обслуживание с точки зрения надежности, а не с инженерной точки зрения, становится ясно, что трансформаторы — своего рода рыжеволосые пасынки, хотя они и являются сердцем электрической системы. Почему? Давайте посмотрим поближе. Индустрия надежности выросла из индустрии технического обслуживания. В основе индустрии технического обслуживания лежат компьютеризированные системы управления техническим обслуживанием… Продолжить чтение Промах: зачем использовать CMMS для электрических систем?
Почему? Давайте посмотрим поближе. Индустрия надежности выросла из индустрии технического обслуживания. В основе индустрии технического обслуживания лежат компьютеризированные системы управления техническим обслуживанием… Продолжить чтение Промах: зачем использовать CMMS для электрических систем?
Как вице-президент по надежности в моей компании, я часто встречаю клиентов, когда они находятся в тирании срочности. У них будет серьезная проблема, множество вопросов и важное решение.Совсем недавно я был с одним из наших клиентов, когда он стоял перед одним из тех важных решений. Это было тяжело. Этот клиент отвечает за сталелитейный завод с 14 заводами. … Продолжайте читать «Данные, информация и мудрость».
Создание сетей Transformer проще и эффективнее
Сети Transformer значительно улучшили многие области глубокого обучения, включая машинный перевод, понимание текста и обработку речи и изображений. Какими бы мощными ни были эти сети, они очень требовательны к вычислительным ресурсам как во время обучения, так и во время логического вывода, что ограничивает их масштабное использование, особенно для последовательностей с долгосрочными зависимостями. Новое исследование Facebook AI направлено на то, чтобы сделать модель Transformer проще и эффективнее.
Новое исследование Facebook AI направлено на то, чтобы сделать модель Transformer проще и эффективнее.
Чтобы обеспечить более широкое использование этой мощной архитектуры глубокого обучения, мы предлагаем два новых метода. Во-первых, адаптивная продолжительность концентрации внимания — это способ сделать сети Transformer более эффективными для более длинных предложений. С помощью этого метода мы смогли увеличить объем внимания Transformer до более чем 8000 токенов без значительного увеличения времени вычислений или объема памяти. Второй, всесторонний уровень — это способ упростить модельную архитектуру сетей Transformer.Даже с гораздо более простой архитектурой наша сеть с полным вниманием соответствовала современным характеристикам сетей Transformer. Мы считаем, что эта работа по повышению эффективности сетей Transformer является важным шагом на пути к более широкой адаптации.
Адаптивный объем внимания
Целью данного исследования является повышение вычислительной эффективности сетей Transformer, особенно при обработке очень длинных последовательностей. Обнаружение долгосрочных отношений в данных требует более длительного внимания.Тем не менее, увеличение объема внимания также увеличивает время вычислений и объем памяти Transformer.
Обнаружение долгосрочных отношений в данных требует более длительного внимания.Тем не менее, увеличение объема внимания также увеличивает время вычислений и объем памяти Transformer.
В наших экспериментах с Трансформерами мы заметили, что не все головы внимания используют свое внимание в полной мере. Фактически, в задаче моделирования языка на уровне символов большинство голов использовали лишь небольшую часть своего внимания. Если мы сможем воспользоваться этим свойством во время обучения, мы сможем значительно сократить время вычислений и объем памяти, поскольку и то, и другое зависит от продолжительности концентрации внимания.К сожалению, мы не знаем, сколько внимания требуется каждой голове. После многих попыток эвристически установить продолжительность концентрации внимания мы поняли, что лучше всего узнать это из самих данных.
Поскольку объем внимания является целым числом (и, следовательно, недифференцируемым), мы не можем напрямую узнать его с помощью обратного распространения, как другие параметры модели. Однако мы можем преобразовать его в непрерывное значение, используя функцию мягкого маскирования. Значение этой функции плавно переходит от 1 к 0, что позволяет дифференцировать ее по длине маскирования.Мы просто вставляем эту маскирующую функцию в каждую головку внимания, чтобы у каждой могла быть разная продолжительность концентрации внимания, определяемая данными.
Однако мы можем преобразовать его в непрерывное значение, используя функцию мягкого маскирования. Значение этой функции плавно переходит от 1 к 0, что позволяет дифференцировать ее по длине маскирования.Мы просто вставляем эту маскирующую функцию в каждую головку внимания, чтобы у каждой могла быть разная продолжительность концентрации внимания, определяемая данными.
Что-то пошло не так
У нас возникли проблемы с воспроизведением этого видео. Чтобы посмотреть видео, обновите веб-браузер.
Благодаря нашему адаптивному механизму концентрации внимания нам удалось увеличить объем внимания Transformer до более чем 8000 токенов без значительного увеличения времени вычислений и объема памяти. В задачах моделирования языка на уровне символов это привело к повышению производительности с меньшим количеством параметров.
В то время как максимальная продолжительность концентрации внимания в модели составляет более 8000 шагов, средняя продолжительность концентрации внимания составляет всего около 200 шагов, что делает модели намного более эффективными. Это отражено в количестве FLOPS на шаг, которое у этих моделей значительно меньше. На приведенном ниже рисунке мы показываем один из таких усвоенных периодов внимания в случае 12-слойной модели с восемью головами в каждом слое. Мы видим, что только пять головок из 96 имеют размах более 1000 шагов.
Это отражено в количестве FLOPS на шаг, которое у этих моделей значительно меньше. На приведенном ниже рисунке мы показываем один из таких усвоенных периодов внимания в случае 12-слойной модели с восемью головами в каждом слое. Мы видим, что только пять головок из 96 имеют размах более 1000 шагов.
Мы выпустили код для проведения экспериментов в нашей статье.Поскольку механизм адаптивного внимания реализован в виде «nn.module» PyTorch, его можно легко интегрировать в другие нейронные модели.
Уровень всеобщего внимания
Далее мы сосредоточились на упрощении архитектуры сетей Transformer. Слой преобразователя состоит из двух подслоев: внутреннего внимания и прямой связи. Хотя уровень самоконтроля считается основным компонентом, подуровень прямой связи важен для высокой производительности, поэтому его размер часто устанавливается в четыре раза больше, чем остальная часть сети.
На первый взгляд подуровни само-внимания и прямой связи сильно отличаются друг от друга.![]() Однако одним простым изменением подуровень прямой связи можно превратить в уровень внимания. Заменив нелинейную функцию ReLU функцией softmax, мы можем интерпретировать ее активации как веса внимания. Кроме того, мы можем рассматривать первое линейное преобразование как ключевые векторы, а второе линейное преобразование как векторы значений. .
Однако одним простым изменением подуровень прямой связи можно превратить в уровень внимания. Заменив нелинейную функцию ReLU функцией softmax, мы можем интерпретировать ее активации как веса внимания. Кроме того, мы можем рассматривать первое линейное преобразование как ключевые векторы, а второе линейное преобразование как векторы значений. .
Воспользовавшись этой интерпретацией, мы объединяем подуровень прямой связи с подуровнем собственного внимания, создавая единый уровень внимания, который мы называем слоем всего внимания .Все, что нам нужно сделать, это добавить дополнительный набор векторов в ключи и значения подуровня само-внимания. Эти дополнительные векторы подобны весам подслоя прямой связи: фиксированные, обучаемые и независимые от контекста. Напротив, ключи и значения, вычисленные из контекста, динамически изменяются в зависимости от текущего контекста.
Что-то пошло не так
У нас возникли проблемы с воспроизведением этого видео. Чтобы посмотреть видео, обновите веб-браузер.
Поскольку дополнительные векторы могут действовать как подуровень с прямой связью и собирать общие сведения о задаче, мы можем удалить все подуровни с прямой связью из сети.В конце концов, наша сеть всеобщего внимания — это просто набор слоев всего внимания. В тестовых задачах языкового моделирования наша сеть с полным вниманием соответствовала современным характеристикам сетей Transformer с гораздо более простой архитектурой. Мы надеемся, что эта упрощенная архитектура откроет путь к лучшему пониманию и улучшению сетей Transformer.
Что такое трансформатор?. Введение в Трансформеры и… | Максим | Внутри Машинное обучение
Новые модели глубокого обучения внедряются с нарастающей скоростью, и иногда бывает сложно уследить за всеми новинками.Тем не менее, одна конкретная модель нейронной сети оказалась особенно эффективной для общих задач обработки естественного языка. Модель называется Transformer и использует несколько методов и механизмов, которые я здесь представлю. Документы, на которые я ссылаюсь в посте, предлагают более подробное и количественное описание.
Документы, на которые я ссылаюсь в посте, предлагают более подробное и количественное описание.
В статье «Внимание — это все, что вам нужно» описываются трансформаторы и то, что называется последовательной архитектурой. Sequence-to-Sequence (или Seq2Seq) — это нейронная сеть, которая преобразует заданную последовательность элементов, например последовательность слов в предложении, в другую последовательность.(Ну, это может вас не удивить, учитывая название.) Модели
Seq2Seq особенно хороши при переводе, когда последовательность слов одного языка преобразуется в последовательность разных слов другого языка. Популярным выбором для этого типа моделей являются модели на основе долговременной памяти (LSTM). С данными, зависящими от последовательности, модули LSTM могут придать смысл последовательности, запоминая (или забывая) части, которые он считает важными (или неважными). Предложения, например, зависят от последовательности, поскольку порядок слов имеет решающее значение для понимания предложения. LSTM — естественный выбор для этого типа данных.
Модели Seq2Seq состоят из кодировщика и декодера. Кодировщик берет входную последовательность и отображает ее в пространстве более высокой размерности (n-мерный вектор). Этот абстрактный вектор подается в декодер, который превращает его в выходную последовательность. Выходная последовательность может быть на другом языке, символами, копией входных данных и т. д.
Представьте себе кодировщика и декодера как людей-переводчиков, говорящих только на двух языках. Их родным языком является их родной язык, который различается у них обоих (т.г. немецкий и французский), а их второй язык — воображаемый, общий для них. Чтобы перевести немецкий язык на французский, кодировщик преобразует немецкое предложение в другой известный ему язык, а именно в воображаемый язык. Поскольку декодер может читать этот воображаемый язык, теперь он может переводить с этого языка на французский.![]() Вместе модель (состоящая из кодировщика и декодера) может переводить с немецкого на французский язык!
Вместе модель (состоящая из кодировщика и декодера) может переводить с немецкого на французский язык!
Предположим, что изначально ни Кодировщик, ни Декодер не очень хорошо говорят на воображаемом языке.Чтобы научиться этому, мы обучаем их (модель) на множестве примеров.
Самый простой выбор для кодировщика и декодера модели Seq2Seq — один LSTM для каждого из них.
Вам интересно, когда Трансформер наконец вступит в игру, не так ли?
Нам нужна еще одна техническая деталь, чтобы упростить понимание Трансформеров: Внимание . Механизм внимания просматривает входную последовательность и на каждом этапе решает, какие другие части последовательности важны.Звучит абстрактно, но позвольте мне пояснить на простом примере: читая этот текст, вы всегда сосредотачиваетесь на слове, которое читаете, но в то же время ваш разум все еще удерживает в памяти важные ключевые слова текста, чтобы обеспечить контекст.![]()
Аналогично работает механизм внимания для данной последовательности. Для нашего примера с человеческим кодировщиком и декодером представьте, что вместо того, чтобы просто записать перевод предложения на воображаемый язык, кодировщик также записывает ключевые слова, важные для семантики предложения, и передает их декодеру в дополнение к обычному переводу.Эти новые ключевые слова значительно упрощают перевод для декодера, потому что он знает, какие части предложения важны и какие ключевые термины определяют контекст предложения.
Другими словами, для каждого ввода, который LSTM (кодировщик) считывает, механизм внимания одновременно учитывает несколько других входов и решает, какие из них важны, приписывая этим входам разные веса. Затем декодер примет в качестве входных данных закодированное предложение и веса, предоставленные механизмом внимания.Подробнее о внимании читайте в этой статье. А для более научного подхода, чем тот, который представлен, прочитайте о различных подходах, основанных на внимании, для моделей «последовательность-последовательность» в этой замечательной статье под названием «Эффективные подходы к нейронному машинному переводу на основе внимания».
В статье «Внимание — это все, что вам нужно» представлена новая архитектура под названием Transformer. Как видно из названия, он использует механизм внимания, который мы видели ранее. Как и LSTM, Transformer представляет собой архитектуру для преобразования одной последовательности в другую с помощью двух частей (кодировщика и декодера), но отличается от ранее описанных/существующих моделей последовательностей к последовательностям тем, что не подразумевает никаких рекуррентных сетей ( ГРУ, ЛСТМ и др.).
Рекуррентные сети до сих пор были одним из лучших способов зафиксировать временные зависимости в последовательностях. Тем не менее, команда, представившая документ, доказала, что архитектура, содержащая только механизмы внимания без RNN (рекуррентных нейронных сетей), может улучшить результаты в задаче перевода и других задачах! Одно улучшение в задачах на естественном языке представлено командой, представляющей BERT: BERT: предварительное обучение глубоких двунаправленных преобразователей для понимания языка.![]()
Итак, что такое Трансформер?
Изображение стоит тысячи слов, с него и начнем!
Рис. 1. Из книги «Внимание — это все, что вам нужно» Васвани и др.Кодировщик находится слева, а декодер — справа. И кодировщик, и декодер состоят из модулей, которые можно устанавливать друг на друга несколько раз, что описано на рисунке как Nx . Мы видим, что модули состоят в основном из слоев Multi-Head Attention и Feed Forward. Входные и выходные данные (целевые предложения) сначала встраиваются в n-мерное пространство, поскольку мы не можем напрямую использовать строки.
Одной небольшой, но важной частью модели является позиционное кодирование различных слов.Поскольку у нас нет рекуррентных сетей, которые могли бы помнить, как последовательности вводятся в модель, нам нужно каким-то образом присвоить каждому слову/части в нашей последовательности относительное положение, поскольку последовательность зависит от порядка ее элементов. Эти позиции добавляются к встроенному представлению (n-мерному вектору) каждого слова.
Эти позиции добавляются к встроенному представлению (n-мерному вектору) каждого слова.
Давайте подробнее рассмотрим эти кубики внимания с несколькими головками в модели:
Начнем с левого описания механизма внимания.Это не очень сложно и может быть описано следующим уравнением:
Q — матрица, содержащая запрос (векторное представление одного слова в последовательности), K — все ключи (векторные представления всех слов в последовательности) и V — значения, которые снова являются векторными представлениями всех слов в последовательности. Для кодера и декодера, модулей внимания с несколькими головками, V состоит из той же последовательности слов, что и Q. Однако для модуля внимания, учитывающего последовательности кодера и декодера, V отличается от последовательности, представленной Q.
Чтобы немного упростить это, мы могли бы сказать, что значения в V умножаются и суммируются с некоторыми весами внимания a, , где наши веса определяются как:
Это означает, что веса a определяются как как на каждое слово последовательности (представленное буквой Q) влияют все остальные слова последовательности (представленные буквой K). Кроме того, функция SoftMax применяется к весам и , чтобы получить распределение от 0 до 1. Эти веса затем применяются ко всем словам в последовательности, введенной в V (те же векторы, что и Q для кодировщика и декодера, но разные). для модуля с входами энкодера и декодера).
Кроме того, функция SoftMax применяется к весам и , чтобы получить распределение от 0 до 1. Эти веса затем применяются ко всем словам в последовательности, введенной в V (те же векторы, что и Q для кодировщика и декодера, но разные). для модуля с входами энкодера и декодера).
На рисунке справа показано, как этот механизм внимания может быть распараллелен в несколько механизмов, которые можно использовать параллельно. Механизм внимания повторяется несколько раз с линейными проекциями Q, K и V. Это позволяет системе учиться на различных представлениях Q, K и V, что полезно для модели. Эти линейные представления выполняются путем умножения Q, K и V на весовые матрицы W, полученные во время обучения.
Эти матрицы Q, K и V различны для каждой позиции модулей внимания в структуре в зависимости от того, находятся ли они в кодере, декодере или между кодером и декодером.Причина в том, что мы хотим отслеживать либо всю входную последовательность кодировщика, либо часть входной последовательности декодера.![]() Модуль внимания с несколькими головками, который соединяет кодер и декодер, гарантирует, что входная последовательность кодера учитывается вместе с входной последовательностью декодера до заданной позиции.
Модуль внимания с несколькими головками, который соединяет кодер и декодер, гарантирует, что входная последовательность кодера учитывается вместе с входной последовательностью декодера до заданной позиции.
После головок с множественным вниманием как в кодере, так и в декодере у нас есть уровень точечной прямой связи. Эта маленькая сеть с прямой связью имеет одинаковые параметры для каждой позиции, что можно описать как отдельное идентичное линейное преобразование каждого элемента из заданной последовательности.
ДрессировкаКак дрессировать такого «зверя»? Обучение и вывод на моделях Seq2Seq немного отличается от обычной задачи классификации. То же самое верно и для Трансформеров.
Мы знаем, что для обучения модели задачам перевода нам нужны два предложения на разных языках, которые являются переводами друг друга. Когда у нас будет много пар предложений, мы можем начать обучение нашей модели. Допустим, мы хотим перевести с французского на немецкий. Нашим закодированным вводом будет предложение на французском языке, а вводом для декодера будет предложение на немецком языке.Однако вход декодера будет сдвинут вправо на одну позицию. ..Подождите, почему?
Одна из причин заключается в том, что мы не хотим, чтобы наша модель научилась копировать входные данные нашего декодера во время обучения, но мы хотим узнать, что, учитывая последовательность кодировщика и конкретную последовательность декодера, которая уже была замечена моделью, мы предсказываем следующее слово/символ.
Если мы не изменим последовательность декодера, модель научится просто «копировать» ввод декодера, поскольку целевое слово/символ для позиции i будет словом/символом i на входе декодера.Таким образом, сдвигая вход декодера на одну позицию, наша модель должна предсказать целевое слово/символ для позиции i , увидев только слово/символы 1, …, i-1 в последовательности декодера.![]() Это не позволяет нашей модели изучить задачу копирования/вставки. Мы заполняем первую позицию ввода декодера токеном начала предложения, поскольку в противном случае это место было бы пустым из-за сдвига вправо. Точно так же мы добавляем маркер конца предложения к входной последовательности декодера, чтобы отметить конец этой последовательности, и он также добавляется к целевому выходному предложению.Через мгновение мы увидим, насколько это полезно для вывода результатов.
Это не позволяет нашей модели изучить задачу копирования/вставки. Мы заполняем первую позицию ввода декодера токеном начала предложения, поскольку в противном случае это место было бы пустым из-за сдвига вправо. Точно так же мы добавляем маркер конца предложения к входной последовательности декодера, чтобы отметить конец этой последовательности, и он также добавляется к целевому выходному предложению.Через мгновение мы увидим, насколько это полезно для вывода результатов.
Это справедливо для моделей Seq2Seq и Transformer. В дополнение к смещению вправо Преобразователь применяет маску к входным данным в первом модуле внимания с несколькими головками, чтобы избежать просмотра потенциальных «будущих» элементов последовательности. Это характерно для архитектуры Transformer, потому что у нас нет RNN, где мы могли бы последовательно вводить нашу последовательность. Здесь мы вводим все вместе, и если бы не было маски, внимание с несколькими головками рассматривало бы всю входную последовательность декодера в каждой позиции.
Процесс подачи правильного сдвинутого ввода в декодер также называется принуждением учителя, как описано в этом блоге.
Целевая последовательность, которую мы хотим использовать для наших расчетов потерь, — это просто ввод декодера (немецкое предложение) без его сдвига и с токеном конца последовательности в конце.
ВыводВывод с этими моделями отличается от обучения, что имеет смысл, потому что в конце мы хотим перевести французское предложение без немецкого предложения.Хитрость здесь заключается в том, чтобы повторно передать нашу модель для каждой позиции выходной последовательности, пока мы не встретим токен конца предложения.
Более пошаговый метод:
- Введите полную последовательность кодировщика (предложение на французском языке), а в качестве входных данных декодера мы возьмем пустую последовательность с токеном начала предложения в первой позиции. Это выведет последовательность, в которой мы возьмем только первый элемент.
- Этот элемент будет помещен во вторую позицию входной последовательности нашего декодера, которая теперь содержит токен начала предложения и первое слово/символ.
- Введите в модель последовательность энкодера и новую последовательность декодера. Возьмите второй элемент вывода и поместите его во входную последовательность декодера.
- Повторяйте это, пока не предскажете токен конца предложения, который отмечает конец перевода.
Мы видим, что нам нужно несколько раз пройти через нашу модель, чтобы перевести наше предложение.
Я надеюсь, что эти описания сделали архитектуру Transformer немного более понятной для всех, начиная с Seq2Seq и структур кодер-декодер.
Мы видели архитектуру Transformer и знаем из литературы и авторов книги «Внимание — это все, что вам нужно», что эта модель очень хорошо справляется с языковыми задачами.![]() Теперь давайте протестируем Transformer на примере использования.
Теперь давайте протестируем Transformer на примере использования.
Вместо задачи перевода давайте реализуем прогноз временных рядов для почасового потока электроэнергии в Техасе, предоставленный Советом по надежности электроснабжения Техаса (ERCOT). Вы можете найти почасовые данные здесь.
Большое подробное объяснение Transformer и его реализации предоставлено harvardnlp.Если вы хотите углубиться в архитектуру, я рекомендую пройтись по этой реализации.
Поскольку мы можем использовать основанные на LSTM модели последовательностей для построения многошаговых прогнозов, давайте взглянем на Transformer и его способность делать такие прогнозы. Однако сначала нам нужно внести несколько изменений в архитектуру, так как мы работаем не с последовательностями слов, а со значениями. Кроме того, мы делаем авторегрессию, а не классификацию слов/символов.
Данные Имеющиеся данные дают нам почасовую нагрузку для всей зоны управления ERCOT. Я использовал данные с 2003 по 2015 год в качестве обучающей выборки и 2016 год в качестве тестовой выборки. Имея только значение нагрузки и метку времени загрузки, я расширил метку времени на другие функции. Из временной метки я извлек день недели, которому он соответствует, и закодировал его горячим способом. Кроме того, я использовал год (2003, 2004, …, 2015) и соответствующий час (1, 2, 3, …, 24) в качестве самого значения.Это дает мне всего 11 функций для каждого часа дня. В целях сходимости я также нормализовал нагрузку ERCOT, разделив ее на 1000.
Я использовал данные с 2003 по 2015 год в качестве обучающей выборки и 2016 год в качестве тестовой выборки. Имея только значение нагрузки и метку времени загрузки, я расширил метку времени на другие функции. Из временной метки я извлек день недели, которому он соответствует, и закодировал его горячим способом. Кроме того, я использовал год (2003, 2004, …, 2015) и соответствующий час (1, 2, 3, …, 24) в качестве самого значения.Это дает мне всего 11 функций для каждого часа дня. В целях сходимости я также нормализовал нагрузку ERCOT, разделив ее на 1000.
Чтобы предсказать заданную последовательность, нам нужна последовательность из прошлого. Размер этих окон может варьироваться от варианта использования к варианту использования, но здесь, в нашем примере, я использовал почасовые данные за предыдущие 24 часа, чтобы предсказать следующие 12 часов. Помогает то, что мы можем настроить размер этих окон в зависимости от наших потребностей. Например, мы можем изменить это на ежедневные данные вместо почасовых.
В качестве первого шага нам нужно удалить вложения, так как у нас уже есть числовые значения на входе. Вложение обычно отображает заданное целое число в n-мерное пространство. Здесь вместо использования встраивания я просто использовал линейное преобразование для преобразования 11-мерных данных в n-мерное пространство. Это похоже на вложение со словами.
Нам также необходимо удалить слой SoftMax из вывода Transformer, потому что наши выходные узлы — это не вероятности, а реальные значения.
После этих незначительных изменений можно начинать обучение!
Как уже упоминалось, я использовал принуждение учителя для обучения. Это означает, что кодировщик получает окно из 24 точек данных в качестве входных данных, а вход декодера представляет собой окно из 12 точек данных, где первая является значением «начало последовательности», а следующие точки данных являются просто целевой последовательностью. Введя в начале значение «начало последовательности», я сдвинул вход декодера на одну позицию относительно целевой последовательности.
Введя в начале значение «начало последовательности», я сдвинул вход декодера на одну позицию относительно целевой последовательности.
Я использовал 11-мерный вектор только с -1 в качестве значений «начало последовательности». Конечно, это можно изменить, и, возможно, было бы полезно использовать другие значения в зависимости от варианта использования, но для этого примера это работает, поскольку у нас никогда не бывает отрицательных значений ни в одном измерении входных/выходных последовательностей.
Функция потерь для этого примера представляет собой просто среднеквадратичную ошибку.
Результаты Два графика ниже показывают результаты. Я взял среднее значение почасовых значений в день и сравнил его с правильными значениями.Первый график показывает 12-часовые прогнозы с учетом 24 предыдущих часов. Для второго графика мы предсказали один час, учитывая 24 предыдущих часа. Мы видим, что модель очень хорошо улавливает некоторые колебания. Среднеквадратическая ошибка для обучающего набора составляет 859, а для проверочного набора — 4106 для 12-часовых прогнозов и 2583 для 1-часовых прогнозов. Это соответствует средней абсолютной процентной ошибке предсказания модели 8,4% для первого графика и 5,1% для второго.
Результаты показывают, что можно использовать архитектуру Transformer для прогнозирования временных рядов. Однако во время оценки это показывает, что чем больше шагов мы хотим спрогнозировать, тем выше будет ошибка. Первый график (рис. 3) выше был получен с использованием 24 часов для прогнозирования следующих 12 часов. Если мы прогнозируем только один час, результаты намного лучше, как мы видим на втором графике (рис. 4).
Есть много возможностей для экспериментов с параметрами Transformer, такими как количество слоев декодера и кодировщика и т. д. Это не было задумано как идеальная модель, и с лучшей настройкой и обучением результаты, вероятно, улучшатся.
д. Это не было задумано как идеальная модель, и с лучшей настройкой и обучением результаты, вероятно, улучшатся.
Ускорение обучения с использованием графических процессоров может сильно помочь. Я использовал локальную платформу Watson Studio для обучения своей модели с помощью графических процессоров и позволил ей работать там, а не на моей локальной машине. Вы также можете ускорить обучение с помощью графических процессоров машинного обучения Watson, которые бесплатны до определенного времени обучения! Посмотрите мой предыдущий блог, чтобы узнать, как это можно легко интегрировать в ваш код.
Большое спасибо за то, что прочитали это, и я надеюсь, что смог прояснить некоторые понятия для людей, которые только начинают вникать в глубокое обучение!
Microsoft и NVIDIA представляют мультимодальные преобразователи с эффективными параметрами для обучения видеопредставлению
Понимание видео — одна из самых сложных проблем в области искусственного интеллекта, и важным базовым требованием является изучение мультимодальных представлений, которые собирают информацию об объектах, действиях, звуках и их статистических зависимостях на большом расстоянии от аудиовизуальных сигналов. В последнее время трансформеры добились успеха в задачах на зрение и язык, таких как создание подписей к изображениям и визуальные ответы на вопросы, благодаря их способности изучать мультимодальные контекстные представления. Однако сквозное обучение мультимодальных преобразователей затруднено из-за чрезмерных требований к памяти. На самом деле, большинство существующих преобразователей зрения и языка полагаются на предварительно обученные преобразователи языка для их успешного обучения.
В последнее время трансформеры добились успеха в задачах на зрение и язык, таких как создание подписей к изображениям и визуальные ответы на вопросы, благодаря их способности изучать мультимодальные контекстные представления. Однако сквозное обучение мультимодальных преобразователей затруднено из-за чрезмерных требований к памяти. На самом деле, большинство существующих преобразователей зрения и языка полагаются на предварительно обученные преобразователи языка для их успешного обучения.
Сегодня в сотрудничестве с NVIDIA Research мы рады объявить о нашей работе: «Параметрически эффективные мультимодальные преобразователи для обучения видеопредставлению.В этой статье, которая была принята на Международной конференции по обучающим представлениям (ICLR 2021), мы предлагаем подход к уменьшению размера мультимодальных преобразователей до 97 процентов за счет механизмов разделения веса. Это позволяет нам обучать нашу модель от начала до конца на видеопоследовательностях продолжительностью 30 секунд (480 кадров с выборкой 16 кадров в секунду), что является значительным отличием от большинства существующих моделей вывода видео, которые обрабатывают клипы короче 10 секунд, и достичь конкурентоспособность в различных задачах на понимание видео.
Агрессивное совместное использование параметров в трансформаторах
Рисунок 1. Наша модель состоит из аудио- и визуальных сверточных нейронных сетей, аудио- и визуальных преобразователей и мультимодального преобразователя.Наша модель состоит из пяти компонентов: звуковых и визуальных сверточных нейронных сетей (CNN), звуковых и визуальных преобразователей и мультимодального преобразователя. Две CNN кодируют звуковые и визуальные сигналы из односекундных клипов соответственно, а три преобразователя кодируют звуковые, визуальные и аудиовизуальные сигналы из всей входной последовательности (30 секунд).Вся модель содержит 155 миллионов весовых параметров, а три преобразователя потребляют 128 миллионов параметров, или 82,6 процента от общего числа. Обучение на 30-секундном видео интенсивно использует память графического процессора, требует небольших размеров пакетов и длительного времени обучения.
Рисунок 2. Мы разделяем параметры как для преобразователей, так и для слоев внутри каждого преобразователя. Чтобы решить эту проблему, мы уменьшаем размер модели, разделяя параметры веса с помощью двух стратегий.Первая стратегия распределяет веса по слоям внутри каждого преобразователя, рассматривая преобразователь как развернутую рекуррентную сеть. Как показано на рисунке 2(b), это уменьшает параметры на 83 процента (со 128 миллионов до 22 миллионов). Вторая стратегия включает частичное разделение веса с факторизацией низкого ранга, где мы факторизуем каждую весовую матрицу преобразователя в виде \(W\)=\(U\)\(Σ\)\(V\) и разделяем \( U\) между трансформаторами, сохраняя \(Σ\)\(V\) закрытыми для каждого трансформатора. Эта стратегия, изображенная на рисунке 2(c), помогает нашей модели эффективно фиксировать лежащую в основе динамику между модальностями: \(U\) моделирует динамику, разделяемую модальностями, а \(Σ\) и \(V\) моделирует динамику, специфичную для модальности. .Факторизация и частичное совместное использование обеспечивают сокращение параметров на 88 процентов. Мы дополнительно уменьшаем параметры, накладывая низкоранговое ограничение на параметр \(Σ\), достигая 97-процентного коэффициента сокращения, со 128 миллионов параметров всего до 4 миллионов параметров.
Мы дополнительно уменьшаем параметры, накладывая низкоранговое ограничение на параметр \(Σ\), достигая 97-процентного коэффициента сокращения, со 128 миллионов параметров всего до 4 миллионов параметров.
WebDataset: эффективная библиотека ввода-вывода PyTorch для крупномасштабных наборов данных
С помощью этой оптимизированной процедуры обучения мы теперь можем обучать наборы данных петабайтного масштаба с высокой скоростью. Чтобы обеспечить высокую скорость ввода-вывода, требуемую алгоритмом, мы параллельно разработали WebDataset, новую высокопроизводительную структуру ввода-вывода для PyTorch.Он обеспечивает эффективный доступ к наборам данных, хранящимся в tar-архивах POSIX, и использует только последовательный/потоковый доступ к данным. Это дает существенные преимущества в производительности во многих вычислительных средах и имеет важное значение для крупномасштабного обучения, такого как наборы видеоданных.
Отрицательная выборка с учетом содержимого
Мы обучаем нашу модель, используя контрастные цели обучения.![]() В контрастном обучении поиск информативных отрицательных образцов необходим для сходимости модели. Мы разрабатываем новую стратегию негативной выборки с учетом содержания, которая в достаточной степени отдает предпочтение негативам, подобно положительному экземпляру.В частности, мы вычисляем нормализованное попарное сходство в пространстве вложений CNN и рассматриваем их как вероятности выборки, так что чем больше выборка похожа на положительную, тем выше вероятность того, что она будет выбрана как отрицательная.
В контрастном обучении поиск информативных отрицательных образцов необходим для сходимости модели. Мы разрабатываем новую стратегию негативной выборки с учетом содержания, которая в достаточной степени отдает предпочтение негативам, подобно положительному экземпляру.В частности, мы вычисляем нормализованное попарное сходство в пространстве вложений CNN и рассматриваем их как вероятности выборки, так что чем больше выборка похожа на положительную, тем выше вероятность того, что она будет выбрана как отрицательная.
Производительность нисходящего потока
Наша модель показала конкурентоспособные результаты в нескольких тестах, включающих аудио- и/или визуальные модальности коротких или длинных клипов. В таблице 1 показаны различные компоненты нашей модели, хорошо обобщающие задачи, например визуальная CNN для распознавания коротких действий (UCF-101), аудио-CNN для короткой классификации звуков окружающей среды (ESC-50) и преобразователи для длинного аудиовизуального видео. классификация (шарады и кинетики-звуки).Наши результаты демонстрируют универсальность этой модели: после предварительной подготовки мы можем использовать различные компоненты, подходящие для последующих сценариев.
классификация (шарады и кинетики-звуки).Наши результаты демонстрируют универсальность этой модели: после предварительной подготовки мы можем использовать различные компоненты, подходящие для последующих сценариев.
С нетерпением жду
Модели трансформаторов с большими параметрами дают впечатляющие результаты при выполнении множества сложных задач, но растет обеспокоенность тем, что проведение исследований в этом направлении ограничено учреждениями с большими вычислительными ресурсами.В этой работе мы представили подход к уменьшению размера мультимодальных преобразователей до 97 процентов и сохранению конкурентоспособных результатов в стандартных тестах видео, что делает их более доступными для учреждений с ограниченными вычислительными ресурсами.![]() Чтобы ускорить исследования в этом направлении, мы открыли исходный код и в ближайшие недели выпустим контрольные точки предварительно обученной модели на GitHub. Мы надеемся, что наше исследование откроет исследовательские возможности в крупномасштабной предварительной подготовке для учреждений с ограниченными вычислительными ресурсами
Чтобы ускорить исследования в этом направлении, мы открыли исходный код и в ближайшие недели выпустим контрольные точки предварительно обученной модели на GitHub. Мы надеемся, что наше исследование откроет исследовательские возможности в крупномасштабной предварительной подготовке для учреждений с ограниченными вычислительными ресурсами
Подтверждение
Это исследование было проведено замечательной командой исследователей из Сеульского национального университета (Санхо Ли, Ёнджэ Ю и Гунхи Ким), NVIDIA Research (Томас Брюэль и Ян Каутц) и Microsoft Research (Йель Сон).
типов трансформаторов — Блог AllumiaX
Дата публикации: 26 сентября 2020 г. Последнее обновление: 26 сентября 2020 г. Абдур РехманСуществуют различные типы трансформаторов, каждый из которых имеет свое применение. Однако основная цель их использования одна и та же – преобразование электроэнергии из одного вида в другой.
В этом блоге мы постараемся рассказать читателям об основах и принципе работы трансформаторов, типах трансформаторов в зависимости от напряжения, среды, использования, конфигурации и места использования, их преимуществах и ограничениях.
👉🏼 Мы запустили новый курс, т. е. IEEE 1584-2018 (Руководство по расчету опасности вспышки дуги) . В этом курсе мы рассказали о введении, истории и некоторых основных изменениях в утвержденном стандарте IEEE 1584-2018. В настоящее время мы предлагаем скидку 50% в течение ограниченного времени. Мы надеемся, что вы присоединитесь к нам и получите от этого пользу.
Трансформатор
Трансформатор — это электрическое устройство, которое можно использовать для передачи энергии от одной цепи к другой с использованием принципов электромагнитной индукции.В трансформаторе есть два типа обмотки: первичная обмотка и вторичная обмотка. Первичная обмотка означает обмотку, к которой подключен источник переменного тока, а вторичная обмотка означает обмотку, к которой подключена нагрузка. Напряжение в цепи будет повышаться или понижаться, но с пропорциональным увеличением или уменьшением номинальных токов.
Принцип работы трансформатора
Работа трансформатора зависит от закона электромагнитной индукции Фарадея.![]() По законам Фарадея
По законам Фарадея
«Скорость изменения потокосцепления во времени прямо пропорциональна ЭДС, индуцированной в проводнике или катушке».
Закон Фарадея
Где,
E = ЭДС индукции
Н = количество витков
dϕ = изменение потока
dt = Изменение во времени
Типы трансформаторов
Трансформатор можно классифицировать по уровню напряжения, среде, использованию, конфигурации и месту использования.Теперь подробно поговорим о каждом виде.
1. На основе уровня напряжения
Ниже перечислены типы трансформаторов в зависимости от уровня напряжения.
- Повышающий трансформатор
- Понижающий трансформатор
- Изолирующий трансформатор
| В зависимости от уровня напряжения | Напряжение | Количество витков | Текущий | Номинальное выходное напряжение | Использует |
|---|---|---|---|---|---|
| Повышающий трансформатор | против > | по сравнению сNp < Ns | IP-адрес > | 220 В — 11 кВ или выше | Распределение питания Дверной звонок, преобразователь напряжения и т. |
| Понижающий трансформатор | Против < Вп | Np > Ns | IP < | 40–220 В, 220–110 В или 110-24В, 20В 10В и т.д. | Силовая передача (Электростанции. Рентгеновские аппараты, микроволновые печи и т.д.) |
| Изолирующий трансформатор | Вс = Вп | Np = Ns | IP = Is | Выходное напряжение, идентичное входному, известное как трансформаторы 1:1 | Изолирующий барьер для обеспечения безопасности, для подавления шума |
 д.
д.Повышающий трансформатор — это устройство, которое преобразует низкое напряжение на первичной стороне в высокое напряжение на вторичной стороне.Первичная обмотка катушки имеет меньшее число витков, чем вторичная обмотка.
- Передача электроэнергии на большие расстояния по низкой цене.
- Помогает уменьшить сопротивление на линии.
- Способность работать непрерывно.
- начинает работу сразу после установки без каких-либо задержек.
- Высокоэффективны и имеют очень небольшие потери.
- Не требует много времени и денег на обслуживание.
- Применение только для работы от переменного тока.
- Использовать круглосуточную систему охлаждения т.е. делать систему громоздкой.
Понижающий трансформатор — это устройство, которое преобразует высокое напряжение на первичной стороне в низкое напряжение на вторичной стороне. Вторичная обмотка катушки имеет меньшее число витков, чем первичная обмотка.
- Простая передача мощности по низкой цене.
- Высокая надежность и эффективность.
- Обеспечивает различные требования к напряжению.
- Требует тщательного обслуживания, что может привести к повреждению трансформатора.
- Волатильность стоимости сырья.
- Устранение неисправности занимает больше времени.
Разделительный трансформатор может быть повышающим или понижающим трансформатором, но значения первичного и вторичного напряжения всегда равны, т. е. соотношение витков всегда равно 1. Это достигается при одинаковом числе витков на первичной и вторичной обмотках.Изолирующие трансформаторы называются «изолированными».
Vs/Vp = Ns/Np Где Ns=Np
- Обеспечьте безопасность электронных компонентов и людей от поражения электрическим током.
- Подавление электрических помех.
- Позволяет избежать контуров заземления.
- Обеспечьте доступное питание, даже если устройство сломано.
- Используются в качестве измерительных трансформаторов
- Выдержит любое необходимое напряжение.
- Создает искажения на вторичной стороне при работе в качестве импульсного трансформатора.
- При работе импульсным сигналом постоянного тока насыщение сердечника уменьшается.
- Высокая стоимость.
2. На основе основного носителя
В зависимости от среды сердечника типы трансформаторов перечислены ниже.
- Трансформатор с воздушным сердечником
- Трансформатор с железным сердечником
- Трансформатор с ферритовым сердечником
| На основе базовой среды | Основной материал | Потокосцепление | Потери на вихревые токи | Нежелание | Взаимная индуктивность | Эффективность | Использует |
|---|---|---|---|---|---|---|---|
| Трансформатор с воздушным сердечником | Немагнитная полоса | По воздуху | Низкий | Высокий | Меньше | Низкий | Радиочастотное приложение |
| Трансформатор с железным сердечником | Несколько пластин из мягкого железа | Сквозь пучок железных пластин | Большой | Меньше | Высокий | Высокий | Распределение электроэнергии |
| Трансформатор с ферритовым сердечником | Ферритовый сердечник | Через окно или отверстие | Очень низкий уровень | Очень низкий уровень | Очень высокий | Очень высокий | Импульсный блок питания |
Трансформаторы с воздушным сердечником предназначены для передачи высокочастотных токов, т. е.например, используемые в радиопередатчиках и устройствах связи и т. д. Как следует из названия, эти трансформаторы не имеют твердого сердечника, что делает их очень легкими, что делает их идеальными для портативных электронных устройств небольших размеров. Трансформаторы с воздушным сердечником создают поток с помощью обмоток и проходящего через них воздуха. Это помогает трансформатору с воздушным сердечником полностью устранить нежелательные характеристики ферромагнитного сердечника (потери на вихревые токи, гистерезис, насыщение и т. д.)
е.например, используемые в радиопередатчиках и устройствах связи и т. д. Как следует из названия, эти трансформаторы не имеют твердого сердечника, что делает их очень легкими, что делает их идеальными для портативных электронных устройств небольших размеров. Трансформаторы с воздушным сердечником создают поток с помощью обмоток и проходящего через них воздуха. Это помогает трансформатору с воздушным сердечником полностью устранить нежелательные характеристики ферромагнитного сердечника (потери на вихревые токи, гистерезис, насыщение и т. д.)
- Нулевые искажения.
- Нулевое рассеивание качества сигнала.
- Бесшумная работа.
- Отсутствие потерь на гистерезис и вихревые токи.
- Легче по весу.
- Низкая степень связи (взаимная индуктивность)
- Не подходит для использования в распределительных сетях.
В этом типе трансформатора первичная и вторичная обмотки намотаны на несколько железных пластин.![]() Эти железные пластины обеспечивают идеальную связь с генерируемым потоком и выполняют аналогичные функции в диапазоне звуковых частот.Трансформатор с железным сердечником широко используется и очень эффективен по сравнению с трансформатором с воздушным сердечником.
Эти железные пластины обеспечивают идеальную связь с генерируемым потоком и выполняют аналогичные функции в диапазоне звуковых частот.Трансформатор с железным сердечником широко используется и очень эффективен по сравнению с трансформатором с воздушным сердечником.
- Работа с большими нагрузками с низкой частотой.
- Предлагает меньше сопротивления.
- Высокоэффективный.
- Большие потери на вихревые токи
Трансформатор с ферритовым сердечником означает трансформатор, магнитный сердечник которого состоит из феррита. Ферриты представляют собой непроводящие керамические соединения, ферромагнитные по своей природе. Высокая магнитная проницаемость этих трансформаторов делает их идеальными для различных высокочастотных трансформаторов, регулируемых катушек индуктивности, широкополосных трансформаторов, дросселей общего режима, импульсных источников питания и радиочастотных приложений.
- Магнитный путь с низким магнитным сопротивлением.
- Высокое сопротивление току.
- Обеспечивает низкие потери на вихревые токи на многих частотах.
- Высокие значения магнитной проницаемости, коэрцитивной способности и добротности.
- Низкий коэффициент гистерезиса, чувствительность по постоянному току и искажение сигнала.

- Легко насыщается (плотность потока насыщения обычно <0,5 Тл).
- Проницаемость дрейфует в зависимости от температуры.
3.На основе использования
В зависимости от использования типы трансформаторов перечислены ниже.
- Силовые трансформаторы
- Распределительные трансформаторы
| В зависимости от использования | Типы сети | Рабочее состояние | Колебания нагрузки | Условия обмотки | Изолированный уровень | Расчетная эффективность | Приложение |
|---|---|---|---|---|---|---|---|
| Силовые трансформаторы | Сеть электропередачи более высокого напряжения | Всегда работает с полной нагрузкой | Очень меньше | Первичная обмотка соединена звездой, вторичная — треугольником | Высокий | Максимальная эффективность при 100% нагрузке | Используется на электростанциях и передающих подстанциях |
| Распределительные трансформаторы | Распределительная сеть низкого напряжения | Работает при нагрузке ниже полной, поскольку цикл нагрузки колеблется | Очень высокий | Первичная обмотка соединена треугольником, вторичная — звездой | Низкий | Максимальная эффективность при нагрузке от 60% до 70% | Используется на распределительных станциях, а также в промышленных и бытовых целях |
Основной принцип силового трансформатора заключается в преобразовании входного низкого напряжения в выходное высокое напряжение. Этот трансформатор действует как мост между генератором электроэнергии и первичной распределительной сетью. Он имеет сложную конструкцию из-за высокой выработки электроэнергии и в основном устанавливается на генерирующих станциях и передающих подстанциях. Силовые трансформаторы применяются в сетях передачи более высокого напряжения.
Этот трансформатор действует как мост между генератором электроэнергии и первичной распределительной сетью. Он имеет сложную конструкцию из-за высокой выработки электроэнергии и в основном устанавливается на генерирующих станциях и передающих подстанциях. Силовые трансформаторы применяются в сетях передачи более высокого напряжения.
- Подходит для приложений с высоким напряжением (более 33 кВ).
- Высокий уровень изоляции.
- Минимизируйте потери мощности.
- Экономично.
- Загружается в течение 24 часов на передающей станции, таким образом, потеря ядра и меди будет происходить в течение всего дня.
- Большой размер.
Распределительные трансформаторы
Распределительные трансформаторы являются понижающими трансформаторами и используются в распределительных сетях промышленного и бытового назначения. Эти трансформаторы преобразуют высокое напряжение сети в напряжение, требуемое конечным потребителем, где электрическая энергия распределяется и используется на стороне потребителя.![]() Эти трансформаторы используются для распределения энергии от электростанции к удаленным местам.
Эти трансформаторы используются для распределения энергии от электростанции к удаленным местам.
- Маленький размер.
- Простая установка.
- Низкие магнитные потери.
- Не всегда полностью загружается.
- Рассчитан на КПД 50-70%.
- Низкая плотность потока по сравнению с силовым трансформатором.
- Регулярные колебания нагрузки.
- Зависит от времени.
4.На основе электроснабжения
В зависимости от конфигурации ниже перечислены типы трансформаторов.
- Однофазный трансформатор
- Трехфазный трансформатор
| Электроснабжение | Блок питания | Сеть | Кол-во катушек | Количество клемм | Напряжение | Возможность передачи энергии | Эффективность | Использует |
|---|---|---|---|---|---|---|---|---|
| Однофазный трансформатор | Электропитание через один проводник | Простой | 2 | 4 | Переноска 230 В | Минимум | Меньше | Для бытовой техники |
| Трехфазный трансформатор | Блок питания через трехжильный | Сложный | 6 | 12 | Переноска 413v | Максимум | Высокий | В крупных производствах и для работы с тяжелыми грузами Силовой или распределительный трансформатор |
Когда имеется только одна катушка на первичной стороне и одна катушка на вторичной стороне, такой трансформатор называется однофазным трансформатором. Здесь питание подается через одиночный проводник. Этот тип трансформатора принимает однофазный переменный ток и выдает однофазный переменный ток, как правило, с переменным уровнем напряжения, который работает в единой временной фазе. Эти типы трансформаторов в основном используются в бытовых устройствах.
Здесь питание подается через одиночный проводник. Этот тип трансформатора принимает однофазный переменный ток и выдает однофазный переменный ток, как правило, с переменным уровнем напряжения, который работает в единой временной фазе. Эти типы трансформаторов в основном используются в бытовых устройствах.
- Простая сеть.
- Экономично.
- Самый эффективный блок питания переменного тока мощностью до 1000 Вт.
- Питание только 1-фазной нагрузки.
- используется для легких грузов и небольших электродвигателей.
- Минимальная мощность передачи.
- Произошел сбой питания.
Трехфазный трансформатор означает, что мощность течет по трем проводникам. Трехфазный трансформатор содержит шесть катушек, три катушки на первичной стороне и три катушки на вторичной стороне. Этот тип трансформатора принимает трехфазный переменный ток и выдает трехфазный переменный ток, как правило, с переменным уровнем напряжения, который работает в единой временной фазе. Эти типы трансформаторов в основном используются в качестве силовых или распределительных трансформаторов
Эти типы трансформаторов в основном используются в качестве силовых или распределительных трансформаторов
- Крупногабаритные двигатели или тяжеловесные материалы.
- Передача энергии на большие расстояния посредством магнитного поля.
- Максимальная мощность передачи.
- Сбоев питания не происходит.
- Требуется множество систем охлаждения в зависимости от номинальной мощности трансформатора.
- Сложная сеть.
5.В зависимости от места использования
В зависимости от места использования типы трансформаторов перечислены ниже.
- Внутренние трансформаторы
- Наружные трансформаторы
| В зависимости от места использования | Охлаждающая среда | Стоимость обслуживания | Рабочий уровень звука | Цена | Эффективность | Использует |
|---|---|---|---|---|---|---|
| Сухие трансформаторы (внутренние) | Воздух в качестве охлаждающей среды | Низкий | Существует шумовое загрязнение | Дорогой | Менее эффективный | Общественные места, такие как транспортные узлы и здания компаний |
| Маслонаполненные трансформаторы (наружные) | Масло в качестве охлаждающей среды | Высокий | Нет шумового загрязнения | Дешево | Более эффективный | Для наружного применения, высоконадежное применение |
Внутренние трансформаторы обычно представляют собой трансформаторы сухого типа. Эти трансформаторы используют воздух в качестве охлаждающей среды, и обычно их первичные и вторичные соединения изолированы. Трансформаторы сухого типа устанавливаются в зданиях и вблизи зданий, поскольку они более безопасны для окружающей среды, т.е. менее пожароопасны. Этот тип трансформаторов считается идеальным для торговых центров, больниц, жилых комплексов и других коммерческих помещений.
- Низкая стоимость обслуживания.
- Более безопасный вариант по сравнению с масляным трансформатором.
- Более высокие операционные потери.
- Шумовое загрязнение.
- Дорого.
обычно представляют собой масляные трансформаторы. В этих трансформаторах в качестве охлаждающей среды используется масло, и они предназначены для использования вне помещений из-за вероятности утечки и разлива масла, которые создают риск возгорания, и должны быть защищены от условий окружающей среды.
- Меньше и эффективнее.
- Снижение эксплуатационных расходов.
- Высокая стоимость обслуживания.
- Требовать периодического отбора проб масла.
Это все о различных типах трансформаторов. Мы надеемся, что после прочтения этого блога вы получите ценную информацию и идеи. Если у вас все еще есть какие-либо вопросы, вы можете оставить комментарий в разделе комментариев ниже.
Об авторе
Абдур Рехман — профессиональный инженер-электрик с более чем восьмилетним опытом работы с оборудованием от 208 В до 115 кВ как в сфере коммунального хозяйства, так и в промышленной и коммерческой сфере.Он уделяет особое внимание защите энергетических систем и инженерным исследованиям.
AWS Amplify анонсирует новый GraphQL Transformer v2. Более многофункциональный, гибкий и расширяемый.
Сегодня AWS Amplify анонсирует GraphQL Transformer версии 2, который позволяет разработчикам разрабатывать более многофункциональные, гибкие и расширяемые серверные части приложений на основе GraphQL даже при минимальном опыте работы с облачными средами. AWS Amplify CLI — это цепочка инструментов командной строки, которая помогает разработчикам интерфейсов создавать серверные части приложений в облаке.С помощью Transformer разработчики могут настроить свою серверную модель данных с помощью языка определения схемы GraphQL, а Amplify CLI автоматически преобразует схему в полностью функционирующий API GraphQL с лежащей в его основе облачной инфраструктурой.
AWS Amplify CLI — это цепочка инструментов командной строки, которая помогает разработчикам интерфейсов создавать серверные части приложений в облаке.С помощью Transformer разработчики могут настроить свою серверную модель данных с помощью языка определения схемы GraphQL, а Amplify CLI автоматически преобразует схему в полностью функционирующий API GraphQL с лежащей в его основе облачной инфраструктурой.
Установите последнюю версию Amplify CLI ( npm i -g @aws-amplify/cli ) и давайте рассмотрим 5 основных новых функций GraphQL, запускаемых с GraphQL Transformer v2:
1. Более явное моделирование данных
В GraphQL Transformer v2 мы сделали процесс моделирования более явным, чтобы дать разработчикам больше контроля и более легкое понимание их модели данных с первого взгляда.Клиенты по-прежнему могут легко создать новую таблицу DynamoDB, используя директиву @model . С новым преобразователем вы получаете новые директивы, такие как @primaryKey и @index , для настройки первичных и вторичных индексов.
Кроме того, для создания отношений между моделями данных можно использовать директивы @hasOne , @hasMany , @belongsTo и @manyToMany .
Узнайте больше о моделировании данных GraphQL Transformer v2.
2. Запрет авторизации по умолчанию
Новая система правил авторизации теперь полностью запрещает по умолчанию. Согласовано для каждого правила авторизации, но не беспокойтесь, мы по-прежнему предоставляем механизм для настройки «глобального правила», чтобы помочь вам быстрее приступить к работе. С новым преобразователем правила авторизации в вашей схеме становятся единственным источником правды для доступа к данным на стороне клиента. Кроме того, теперь существует явная иерархия правил, то есть правила уровня поля перезаписывают правила уровня модели, а правила уровня модели перезаписывают глобальные правила.
Кроме того, если вы не уверены в текущей матрице управления доступом вашей модели, вы можете запустить amplify status api -acm <ИМЯ_ВАШЕЙ_МОДЕЛИ> , чтобы получить распечатку того, кто и к чему имеет доступ.
Узнайте больше о правилах авторизации GraphQL Transformer v2.
3. Расширение конвейерных преобразователей, созданных Amplify
Новый Transformer был полностью переписан для использования преобразователей конвейеров AWS AppSync.Это означает более модульный и расширяемый код преобразователя для вас! Теперь мы даем вам возможность «вставить» свою собственную бизнес-логику между резолверами, созданными Amplify, или полностью переопределить резолверы, созданные Amplify. Просто поместите свой собственный преобразователь VTL с правильным соглашением об именах в папку amplify/backend/api/, а затем при следующем усилении Transformer включит пользовательскую бизнес-логику в развернутый GraphQL. API.
Узнайте больше о том, как расширить резолверы, сгенерированные Amplify, или переопределить резолверы, сгенерированные Amplify.
4. Переопределение базовых облачных ресурсов GraphQL API
На прошлой неделе мы объявили о возможности переопределения ресурсов конфигурации IAM, Cognito и S3, созданных Amplify. На этой неделе мы объявляем о возможности переопределения ресурсов GraphQL API, созданных Amplify, и ресурсов REST API. Просто запустите amplify override api, а затем примените изменения на уровне инфраструктуры для любых ресурсов AppSync, DynamoDB, OpenSearch и IAM, созданных API GraphQL.
На этой неделе мы объявляем о возможности переопределения ресурсов GraphQL API, созданных Amplify, и ресурсов REST API. Просто запустите amplify override api, а затем примените изменения на уровне инфраструктуры для любых ресурсов AppSync, DynamoDB, OpenSearch и IAM, созданных API GraphQL.
усилить переопределение API Например, чтобы включить трассировку рентгеновских лучей в AppSync API, примените следующие переопределения:
import { AmplifyApiGraphQlResourceStackTemplate } из '@aws-amplify/cli-extensibility-helper';
переопределение функции экспорта (ресурсы: AmplifyApiGraphQlResourceStackTemplate) {
Ресурсы.api.GraphQLAPI.xrayEnabled = истина
} Узнайте больше о том, как переопределить ресурсы GraphQL API, созданные Amplify.
5. Улучшенная интеграция с OpenSearch
Новый GraphQL Transformer также предоставляет более мощные запросы OpenSearch. Теперь вы можете выполнять запросы OpenSearch, которые ограничены правами доступа текущего пользователя. Запускайте запросы агрегации, такие как минимальное значение (min), максимальное значение (max), сумма значений (sum) или среднее (avg). Кроме того, новый Transformer предоставляет клиентам возможность указывать несколько условий сортировки результатов поиска.
Запускайте запросы агрегации, такие как минимальное значение (min), максимальное значение (max), сумма значений (sum) или среднее (avg). Кроме того, новый Transformer предоставляет клиентам возможность указывать несколько условий сортировки результатов поиска.
запрос MyQuery {
поискСтуденты(
агрегаты: {
type: min, # Указывает, что вы хотите значение "min"
поле: examsCompleted, # Указывает поле для совокупного значения
name: "minimumExams" # предоставляет имя для ссылки в поле ответа
} фильтр: { имя: {подстановочный знак: "Рене*"}}) {
агрегатные элементы {
название
результат {
... на SearchableAggregateScalarResult {
ценность
}
}
}
total # Получить общее количество
}
} Узнайте больше об агрегатах поиска и результатов GraphQL Transformer v2.
Переход на новый GraphQL Transformer с версии 1
Если сегодня вы являетесь клиентом Amplify и используете GraphQL Transformer v1, обязательно ознакомьтесь с руководством по переходу с GraphQL Transformer v1 на v2. Мы предоставляем помощник по миграции, который сканирует вашу текущую схему GraphQL и помогает перенести ее на схему, совместимую с v2.
Мы предоставляем помощник по миграции, который сканирует вашу текущую схему GraphQL и помогает перенести ее на схему, совместимую с v2.
Некоторые возможности v1, такие как использование пользовательских распознавателей, перезаписанных распознавателей или использование реляционного источника данных, нельзя перенести с помощью вспомогательного API-интерфейса amplify migrate.Ознакомьтесь с изменениями, которые Amplify CLI требует ручной миграции, чтобы продолжить.
Новая глава для поддержки Amplify GraphQL
Это лишь 5 основных функций GraphQL Transformer версии 2. Существует целый ряд дополнительных функций (например, поддержка авторизатора Lambda!) и улучшений DX (более короткий рабочий процесс «усилить добавление API»!), которые мы не смогли описать этот пост в блоге. Ознакомьтесь с новой документацией по GraphQL, чтобы глубже изучить все новые функции.
Как всегда, не стесняйтесь обращаться к команде Amplify через GitHub или присоединиться к нашему сообществу Discord.
Добавить комментарий